1. 什么是 Prefix Cache
在模型推理场景下,经常会使用缓存机制来提升吞吐和性能。常见的有两种缓存机制:
- Key-Value Cache (KV Cache),面向的是单次请求的内部,将 Transformer 模型中间计算结果(Key 和 Value)缓存起来,避免重复计算
- Prefix Cache,面向的是多次请求时,利用 Prompt 的公共前缀,避免重复计算。
Prefix Cache 的原理是通过哈希、基数树等结构检测请求的公共前缀,在 prefill 阶段复用之前的计算结果,提升推理性能。
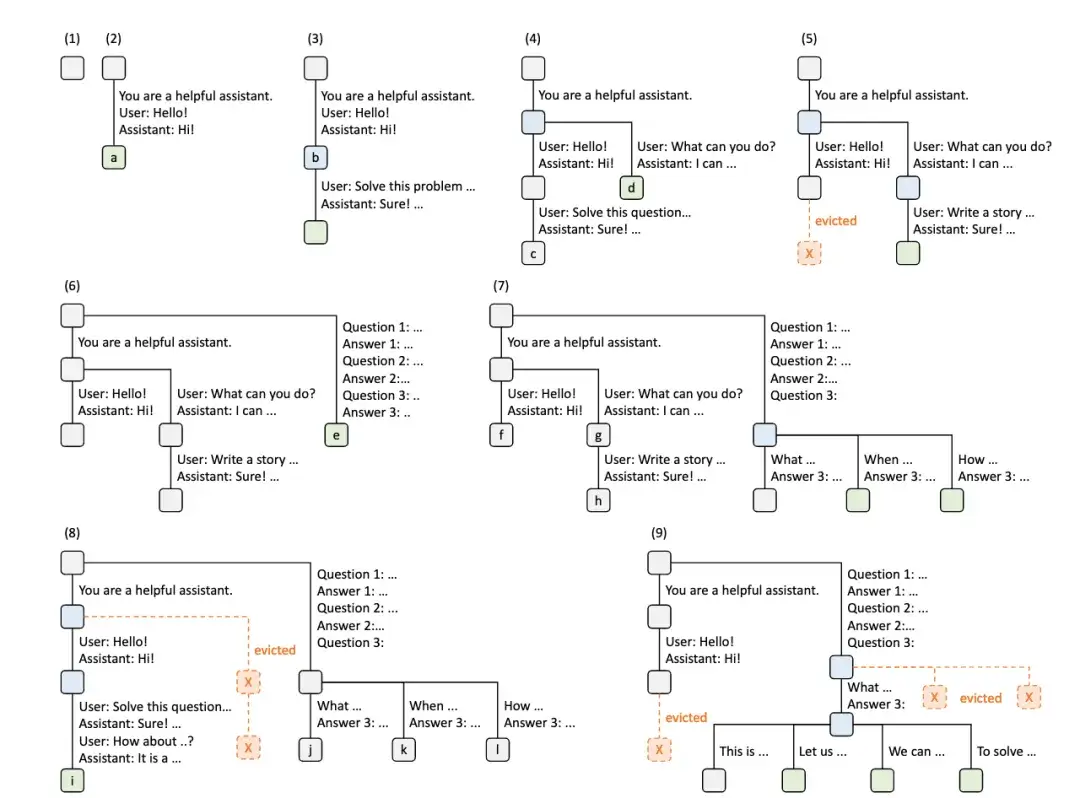
上面这张图就是 Radix Tree (基数树) 在多次请求下构建 Prefix Cache 的示意图,
随着请求的增加,缓存树在不断地调整,既会增加新的节点,也会通过策略删除节点。
Prefix Cache 给 AI 应用开发者的启示是:
- 将 Prompt 不变的部分放在前面,变动的部分放在后面
- 有多个 Prompt 尽量保持相同的前缀
2. 启动环境
为了能够直接使用内置的 benchmark 工具,这里使用 vLLM 的 OpenAI API Server 镜像。
1
2
3
4
5
6
7
8
9
10
11
12
| nerdctl run -it \
--security-opt apparmor=unconfined \
--security-opt seccomp=unconfined \
-p 8000:8000 \
--gpus all \
--ipc=host \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
--name vllm \
--volume /data/models:/data/models \
--entrypoint /bin/bash \
vllm/vllm-openai:v0.10.1.1
|
3. 启动服务
3.1 推理服务
1
2
3
4
5
6
7
8
9
10
11
| export CUDA_VISIBLE_DEVICES=7
python3 -m vllm.entrypoints.openai.api_server \
--model /data/models/Qwen2.5-7B-Instruct \
--served-model-name /data/models/Qwen2.5-7B-Instruct \
--port 8000 \
--gpu_memory_utilization 0.8 \
--max-model-len 4096 \
--max-seq-len-to-capture 8192 \
--max-num-seqs 128 \
--enforce-eager \
--no-enable-prefix-caching
|
1
2
3
4
5
6
7
8
9
10
11
| export CUDA_VISIBLE_DEVICES=7
python3 -m vllm.entrypoints.openai.api_server \
--model /data/models/Qwen2.5-7B-Instruct \
--served-model-name /data/models/Qwen2.5-7B-Instruct \
--port 8000 \
--gpu_memory_utilization 0.8 \
--max-model-len 4096 \
--max-seq-len-to-capture 8192 \
--max-num-seqs 128 \
--enforce-eager \
--enable-prefix-caching
|
3.2 启动客户端
1
| nerdctl exec -it vllm /bin/bash
|
1
2
3
4
5
6
7
| vllm bench serve \
--backend openai \
--model /data/models/Qwen2.5-7B-Instruct \
--dataset-name random \
--random-input-len 1024 \
--num-prompts 1024 \
--request-rate 16
|
1
2
3
4
5
6
7
8
| vllm bench serve \
--backend openai \
--model /data/models/Qwen2.5-7B-Instruct \
--dataset-name sharegpt \
--dataset-path /data/models/ShareGPT_V3_unfiltered_cleaned_split.json \
--random-input-len 1024 \
--num-prompts 1024 \
--request-rate 16
|
4. 测试结果
| times | Dataset | output tokens/s | P99 TTFT (ms) | P99 TPOT (ms) | Prefix Cache Hit Rate (%) |
|---|
| 首次 | random | 1287.99 | 32274.35 | 142.70 | 0.0% |
| 再次 | random | 1283.74 | 32440.12 | 145.42 | 0.0% |
| 首次 | sharegpt | 2759.34 | 143.35 | 35.83 | 0.0% |
| 再次 | sharegpt | 2763.50 | 138.34 | 35.68 | 0.0% |
在测试过程中,会有少量 GPU KV cache 命中。
| times | Dataset | output tokens/s | P99 TTFT (ms) | P99 TPOT (ms) | Prefix Cache Hit Rate (%) |
|---|
| 首次 | random | 1276.67 | 32963.75 | 149.21 | 0.4% |
| 再次 | random | 1275.01 | 33149.52 | 156.06 | 0.8% |
| 首次 | sharegpt | 2754.99 | 135.72 | 35.90 | 0.8% |
| 再次 | sharegpt | 2783.04 | 47.05 | 17.73 | 96.0% |
使用的设备是 NVIDIA A100-SXM4-80GB,从测试结果可以看出,使用 Prefix Cache 在 ShareGPT 数据集上,第二次测试的 Prefix Cache 命中率达到了 96.0%,P99 TTFT 从 138.34ms 降低到了 47.05ms,提升非常明显。
这说明,在显存充足的情况下,如果 Prompt 能够命中缓存,推理的 TTFT、TPOT 都会有显著的提升。
