1.为什么要 PD 分离部署大模型应用
在大模型推理的过程中,有两个串行阶段:
- 处理全量的输入上下文,生成 KV Cache(Prefill 阶段)
- 增量生成新的 token(Decode 阶段)
这两个阶段对资源的需求不一样。Prefill 阶段要计算大量的 KV Cache,Decode 阶段要读取、存储大量的 KV Cache。
如果在一个设备上,同时运行 Prefill 和 Decode 阶段,那么这个设备的计算要够强,显存要够大,相应的价格就更高。
从芯片设计的角度,计算核心越多,占用的硅片面积越大,留给显存接口的面积就越小,能支持的最大显存容量越小。
芯片生产厂商受限于成本、良率、工艺、功耗、国际形势,对单芯片面积进行了限制,Prefill 和 Decode 两个过程对芯片的要求存在矛盾。
既然短期无法解决这个矛盾,那只能将 Prefill 和 Decode 两个过程分别部署在不同的设备上。Prefill 选择计算能力强的芯片,Decode 选择显存容量大的芯片。
当然,如果模型较小、文本较短,单个设备也许就能提供足够的计算和显存资源,就不用 PD 分离部署了。
2. PD 分离应用的请求流量分析
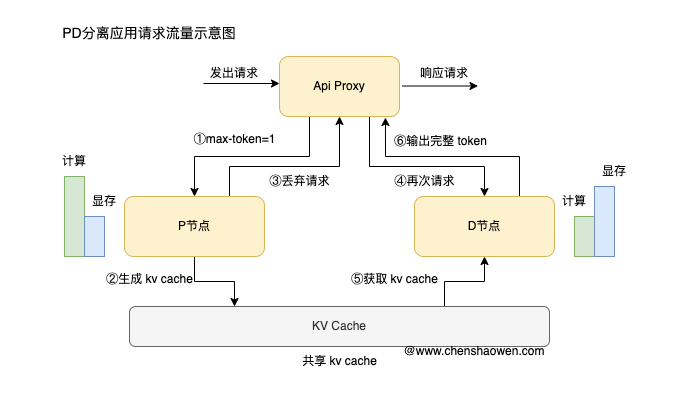
PD 分离的应用需要三个服务:
- API Proxy 服务,接收用户请求,转给 P 节点和 D 节点
- P 节点,负责 Prefill 阶段,生成 KV Cache
- D 节点,负责 Decode 阶段,读取、存储 KV Cache
在部署时,P 节点和 D 节点的配置可以是一样的,只是使用的计算设备不一样。比如 P 节点使用 H200,D 节点使用 H20。API Proxy 服务只使用 CPU,只需要网络对 P 节点和 D 节点低延时即可。
API Proxy 服务是流量的出入口,PD 分离应用的处理如下:
- API Proxy 设置
max_tokens=1,将用户请求转发给 P 节点 - P 节点处理请求,生成 KV Cache,返回第一个 token 给 API Proxy
- API Proxy 丢弃 P 节点的响应
- API Proxy 将用户请求转发给 D 节点
- D 节点处理请求,读取 KV Cache 继续生成 token
- D 节点将生成的 token 返回给 API Proxy
这里会有一些有意思的思考:
- 是不是一定先 P 才 D?能不能直接 D,也许能命中 Cache。这就引出了 NVIDIA 开源的 dynamo 项目
- P、D 共享 KV Cache 的方式有哪些?这就引出了不同的 Connector,利用远端存储、NIXL、NCCL 进行高速传输
- 多个 P 节点和 D 节点如何协同工作?这就引出了 Proxy 服务的设计,如何提高缓存命中率
- 围绕缓存的分级。在 P、D 节点上,都可以配置显存、内存、本地、远端的多级缓存,如何协调
- 超大容量存储池,https://lmcache.ai/kv_cache_calculator.html 可以计算一个大模型的长文本 Cache 块就有 200 MB 以上,如何构建超大容量的缓存池
- KV Cache 的过期和清理策略
- 负载均衡和容错。多个 P、D 节点如何做负载均衡,节点故障如何处理
在实际生产中,这些问题可能都需要考虑。这也给 AI Infra 部署组件带来了新的挑战和机会。我们先部署一个简单的应用,来体验一下 PD 分离,放松一下。
3. vLLM 部署 PD 分离应用
3.1 vLLM 支持的连接器
连接器就是 P 节点和 D 节点共享 KV Cache 的方式。vLLM 目前支持 5 种类型的连接器:
- SharedStorageConnector, 通过共享存储路径进行 KV Cache 共享
- LMCacheConnectorV1,结合 LMCache 缓存和 NIXL 传输 KV Cache
- NixlConnector,基于 NIXL 传输 KV Cache
- P2pNcclConnector,利用 NVIDIA NCCL 进行 KV Cache 传输
- MultiConnector,多种连接器组合
参考 https://docs.vllm.ai/en/latest/features/disagg_prefill.html?h=prefill#why-disaggregated-prefilling
这里使用 SharedStorageConnector 进行演示。
3.2 启动 vLLM 容器环境
1
2
3
4
5
6
7
8
9
10
11
12
| nerdctl run -it \
-p 8000:8000 \
-p 8100:8100 \
-p 8200:8200 \
--gpus all \
--ipc=host \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
--name vllm \
--volume /data/models:/data/models \
--entrypoint /bin/bash \
vllm/vllm-openai:v0.10.1.1
|
后面的命令都在容器内执行。
3.3 部署 P 节点
1
2
3
4
5
6
7
8
| export CUDA_VISIBLE_DEVICES=0
vllm serve /data/models/Qwen2.5-7B-Instruct \
--port 8100 \
--max-model-len 4096 \
--gpu-memory-utilization 0.8 \
--trust-remote-code \
--kv-transfer-config \
'{"kv_connector":"SharedStorageConnector","kv_role":"kv_producer","kv_connector_extra_config":{"shared_storage_path":"/data/models/pd_local_storage"}}'
|
这里的 kv_role 设置为 kv_producer, 表示 P 节点是 KV Cache 的生产者。shared_storage_path 指定了共享存储的路径,P 节点会将生成的 KV Cache 存储在这个路径下。
1
2
3
4
5
6
7
8
| export CUDA_VISIBLE_DEVICES=1
vllm serve /data/models/Qwen2.5-7B-Instruct \
--port 8200 \
--max-model-len 4096 \
--gpu-memory-utilization 0.8 \
--trust-remote-code \
--kv-transfer-config \
'{"kv_connector":"SharedStorageConnector","kv_role":"kv_consumer","kv_connector_extra_config":{"shared_storage_path":"/data/models/pd_local_storage"}}'
|
也可以将两个节点的角色都设置为 kv_both, 既作为 KV Cache 的生产者,也作为消费者。
3.4 启动 AI Proxy 服务
1
2
3
| wget https://raw.githubusercontent.com/vllm-project/vllm/refs/heads/main/benchmarks/disagg_benchmarks/disagg_prefill_proxy_server.py -O /data/models/disagg_prefill_proxy_server.py
wget https://raw.githubusercontent.com/vllm-project/vllm/refs/heads/main/benchmarks/disagg_benchmarks/rate_limiter.py -O /data/models/rate_limiter.py
wget https://raw.githubusercontent.com/vllm-project/vllm/refs/heads/main/benchmarks/disagg_benchmarks/request_queue.py -O /data/models/request_queue.py
|
1
| python3 -m pip install --ignore-installed blinker quart -i https://pypi.tuna.tsinghua.edu.cn/simple
|
1
| python3 /data/models/disagg_prefill_proxy_server.py
|
1
2
3
4
5
6
7
8
| curl -X POST "http://127.0.0.1:8000/v1/completions" \
-H "Content-Type: application/json" \
-d '{
"model": "/data/models/Qwen2.5-7B-Instruct",
"prompt": "介绍一下量子计算的基本原理",
"temperature": 0.7,
"max_tokens": 4000
}'
|
1
| {"id":"cmpl-b46522dbab4c4f9abba2f0e5ff0c9cd7","object":"text_completion","created":1758250381,"model":"/data/models/Qwen2.5-7B-Instruct","choices":[{"index":0,"text":" 量子计算是一种基于量子力学原理的计算方式,它利用量子比特(qubit)代替传统计算机中的二进制位(bit)。量子比特可以处于0和1的叠加态,这意味着一个量子比特可以同时表示0和1,这种特性称为“叠加”。此外,量子比特之间还可以发生纠缠,即两个或多个量子比特之间的状态可以相互关联,即使它们相隔很远,一个量子比特的状态改变也会立即影响到另一个量子比特的状态。\n\n这些特性使得量子计算机在某些特定问题上具有超越经典计算机的优势。例如,在因子分解、搜索算法等领域,量子计算机可以实现指数级加速。量子计算的核心在于如何设计和控制量子比特,以及如何进行量子门操作,以实现特定的量子算法。目前,量子计算仍处于研究和发展阶段,但其潜力巨大,有望在未来带来革命性的变革。","logprobs":null,"finish_reason":"stop","stop_reason":151643,"prompt_logprobs":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":8,"total_tokens":190,"completion_tokens":182,"prompt_tokens_details":null},"kv_transfer_params":null}
|
1
| (EngineCore_0 pid=4206) INFO 09-18 19:53:35 [shared_storage_connector.py:265] External Cache Hit!
|
1
2
3
4
5
6
7
| ls /data/models/pd_local_storage/d41d8cd98f00b204e9800998ecf8427e/
model.layers.0.self_attn.attn.safetensors model.layers.21.self_attn.attn.safetensors
model.layers.1.self_attn.attn.safetensors model.layers.22.self_attn.attn.safetensors
model.layers.10.self_attn.attn.safetensors model.layers.23.self_attn.attn.safetensors
model.layers.11.self_attn.attn.safetensors model.layers.24.self_attn.attn.safetensors
...
|
4. 总结
本篇主要内容如下:
- 对于大模型、长文本的模型推理,Prefill 和 Decode 两个阶段对计算和显存的需求存在矛盾,可以通过 PD 分离部署来解决
- 从 PD 分离应用的请求流量分析,P 节点通过设置
max_tokens=1 生成 KV Cache 并不直接响应请求 - 使用 vLLM 部署 PD 分离应用,体验 P 节点、D 节点和 Proxy 服务的协同工作
