1. 为什么是运维事件
Metrics、Log 维度的观测数据,运维团队通常都有所沉淀。运维事件可以是一个新的切入点,在不影响现有系统稳定性的情况下,引入新的运维能力。
Metrics 表征的是系统状态,Log 表征的是具体代码行为,而 Event 表征的是组件的变化。
而变化是稳定性最大的敌人,运维事件能够更好地捕捉到变化,触发自动化能力。
Metrics 和 Log 的异常检测机制是定时查询,同时配置一定的阈值、持续时间的检测,告警的发出具有一定延时。
运维事件的异常检测机制是实时监听,watch 到事件之后,立即就能触发自动化能力。
最近两年我一直在探索 AI Agent 在运维领域的应用,已经有一些案例可以参考。我们每天有 100w+ 的运维事件产生,经过各种告警和全自动化处理流程,保障着数十个 AI 集群以及上面 AI 应用的稳定运行。
2. 安装事件组件
1
2
3
| helm repo add nats https://nats-io.github.io/k8s/helm/charts/
helm repo update
helm show values nats/nats
|
1
2
| export adminpassword=mypassword
export apppassword=mypassword
|
注意修改一下 storageClassName
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| cat <<EOF > nats-values.yaml
config:
jetstream:
enabled: true
fileStore:
enabled: false
dir: /data
memoryStore:
enabled: true
maxSize: 1Gi
pvc:
enabled: false
storageClassName: my-sc
cluster:
enabled: true
leafnodes:
enabled: true
merge:
accounts:
SYS:
users:
- user: admin
password: ${adminpassword}
APP:
users:
- user: app
password: ${apppassword}
jetstream: true
system_account: SYS
container:
image:
repository: nats
tag: 2.10.20-alpine
natsBox:
container:
image:
repository: nats-box
tag: 0.14.5
reloader:
enabled: true
image:
repository: natsio/nats-server-config-reloader
tag: 0.15.1
EOF
|
如果是多集群,可以参考 https://www.chenshaowen.com/ops/zh/nats.html 配置一个主 Nats 集群,其他集群通过 leafnodes 连接到主集群。
1
2
3
4
5
6
7
8
| helm install myops ops/ops
--version 1.2.0 \
--namespace ops-system \
--create-namespace \
--set controller.env.activeNamespace="ops-system" \
--set controller.env.defaultRuntimeImage="ubuntu:22.04" \
--set event.cluster="mycluster" \
--set event.endpoint="http://app:mypassword@nats-headless.ops-system.svc:4222"
|
https://github.com/shaowenchen/ops 项目通过 watch 的方式监听 Kubernetes 的全部事件,并将其转换为运维事件,存储到了外部的 Nats 集群。经过指标监控确认,Ops 项目不会对 kube-apiserver 或 etcd 产生性能影响。事件一旦被导出,存储到 Nats 之后,不会对 Kubernetes 产生额外的压力。
3. 事件的格式
3.1 命名空间级别事件格式
1
| ops.clusters.{cluster}.namespaces.{namespace}.{resourceType}.{resourceName}.{observation}
|
其中:
- {cluster}: 集群名称(从环境变量 EVENT_CLUSTER 获取)
- {namespace}: Kubernetes 命名空间
- {resourceType}: 资源类型(如 deployments, pods, configmaps 等)
- {resourceName}: 资源名称
- {observation}: 观测类型,可能的值及含义:
- status: 资源状态信息(如运行状态、健康状态等)
- events: 事件信息(如 Kubernetes 事件)
- alerts: 告警信息
- findings: 主动上报的信息和状态
3.2 节点事件格式
1
| ops.clusters.{cluster}.nodes.{nodeName}.{observation}
|
其中:
- {cluster}: 集群名称(从环境变量 EVENT_CLUSTER 获取)
- {nodeName}: 节点名称
- {observation}: 观测类型,可能的值及含义:
- events: 事件信息(如 Kubernetes 事件)
- alerts: 告警信息
- findings: 主动上报的信息和状态
示例:
1
| ops.clusters.mycluster.nodes.mynode.events
|
3.3 通知类的格式
这种事件数据并不是由 Ops 项目从 Kubernetes 中采集,而是用于收集其他系统的各种通知,转化为可被处理的运维事件。
通知事件主题格式:
1
| ops.notifications.providers.{provider}.channels.{channel}.severities.{severity}
|
- {provider}: 通知提供商或系统名称(如 ksyun, ai 等)
- {channel}: 通知渠道类型(如 webhook, email, sms 等)
- {severity}: 严重程度级别(如 info, warning, error, critical 等)
示例:
1
| ops.notifications.providers.ksyun.channels.webhook.severities.critical
|
4. 事件的处理
4.1 直接触发通知
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| apiVersion: crd.chenshaowen.com/v1
kind: EventHooks
metadata:
name: nodes-p0
namespace: ops-system
spec:
keywords:
exclude:
- cn-beijing
include:
- NodeNotReady
- NodeReady
subject: ops.clusters.*.nodes.*.events
type: xiezuo
url: https://x.x.x/api/v1/webhook/send?key=
|
当集群节点未就绪时,立即就会发出通知,这比 Metrics 告警快了分钟级别的时间。
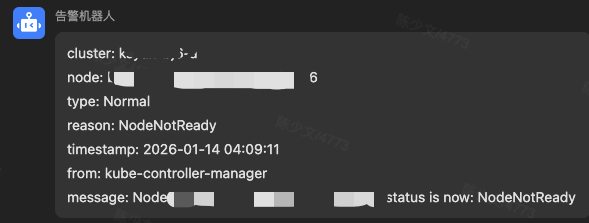
4.2 触发自动化流程
1
2
3
4
5
6
7
8
9
10
11
12
13
| apiVersion: crd.chenshaowen.com/v1
kind: EventHooks
metadata:
name: custom-disable
namespace: ops-system
spec:
additional: 'action: cordon-node'
keywords:
include:
- "10005"
subject: ops.clusters.*.nodes.*.events
type: webhook
url: http://x.x.x.x:x/trigger/action?key=
|
当检测到节点事件中包含 “10005” 时,就会触发自动化流程,执行 “cordon-node” 操作。
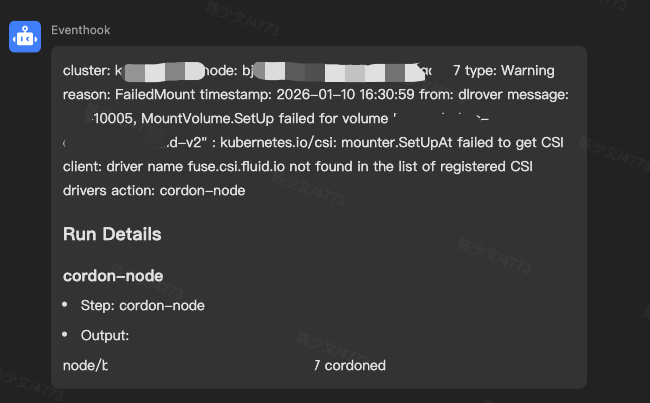
4.3 事件的转换
为了方便消费指定特征的事件,我们会将事件先转换为告警事件。异常处理模块,只需要监听告警事件即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| apiVersion: crd.chenshaowen.com/v1
kind: EventHooks
metadata:
name: convert-clusters-pods-events-to-alerts
namespace: ops-system
spec:
keywords:
include:
- .*(BackOff|OOMKilled|Evicted|NetworkNotReady|Unhealthy|Error|Failed|ImagePullBackOff).*
matchMode: ALL
matchType: REGEX
subject: ops.clusters.*.namespaces.*.pods.*.events
type: event
url: ops.clusters.*.namespaces.*.pods.*.alerts
|
当检测到 ops.clusters.mycluster.namespaces.mynamespace.pods.myapp.events 中包含 BackOff 时,就会创建一个内容相同的 ops.clusters.mycluster.namespaces.mynamespace.pods.myapp.alerts 事件。
4.4 事件的分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| apiVersion: crd.chenshaowen.com/v1
kind: EventHooks
metadata:
name: post-cluster-pod-ops-agent
namespace: ops-system
spec:
additional: clusterpodevents
keywords:
include:
- .*(kube-apiserver-|kube-controller-manager-|kube-scheduler-|kube-proxy-|etcd-|calico-|csi-nfs-|fluid-system).*
matchMode: ANY
matchType: REGEX
subject: ops.clusters.*.namespaces.*.pods.*.alerts
type: webhook
url: http://x.x.x.x:x/api/push
|
而你需要做的就是开发一个 /api/push 接口,接收运维事件,并进行分析和处理。
在我们的系统中,这接口已经汇聚了应用、节点、集群三个维度的运维事件,用于系统性的进行分析。

5. 怎么接入事件
5.1 告警事件的接入
https://github.com/shaowenchen/ops 项目中有一个 ops-server 服务,能够推送和消费运维事件。
1
| http://myops-server.ops-system.svc:80/api/v1/namespaces/ops-system/events/ops.notifications.providers.aliyun.channels.webhook.severities.info
|
1
| http://myops-server.ops-system.svc:80/api/v1/namespaces/ops-system/events/ops.notifications.providers.ksyun.channels.webhook.severities.info
|
这是两个云厂的事件存储 Topic,除此我还对接了内部的告警通知系统,逐步完善系统事件的观测能力。
5.2 taskrun 定时任务
https://github.com/shaowenchen/ops 项目支撑定时任务,可以配置 taskrun 来进行一些定制化的脚本检测,并上报为 findings 事件。
1
2
3
4
5
6
7
8
| apiVersion: crd.chenshaowen.com/v1
kind: TaskRun
metadata:
name: alert-hosts-card
namespace: ops-system
spec:
crontab: 30 * * * *
taskRef: alert-hosts-card
|
在 ops.clusters.*.namespaces.*.hosts.*.findings 中,就会收到这些事件。
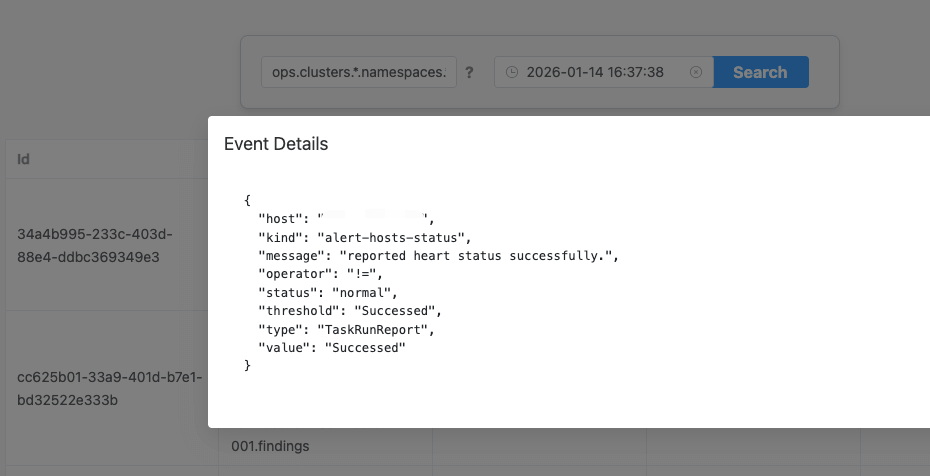
Ops 项目也提供了 web 页面,用于查看这些事件。
6. 总结
2025 年在 AI Agent 运维方向做了一系列的优化,停止迭代之前的 copilot 模式,引入 MCP 统一 Metrics、Log、Event、SOPS 的接入,告警数据的结构化,SOPS 直接触发,SLO 自动分析。
自动化层优化的基石就是运维事件,之前写过一篇 使用事件总线改造运维体系 阐述事件总线在运维体系的重要作用,本篇也算是对事件总线的一次真实落地。
