1.问题描述
背景:一个 Django 开发的 SaaS 应用,对外提供文档服务功能。其中,搜索功能通过 Django Haystack 实现。
问题:搜索功能有时可用,有时不可用。多次测试,发现可用和不可用会交替出现,出现概率各占约 50%。
补充一下搜索功能实现的细节:
Django Haystack 在提供搜索功能之前,需要执行如下命令:
| |
生成索引文件:
| |
只有存在有效索引文件的前提下,才能提供搜索服务。因此,将更新索引的命令,通过 subprocess 在 Python 中直接执行,代码如下:
| |
2. 问题定位
发现服务的可用状态和不可用状态交替出现时,首先想到 Nginx 的默认负载策略就是轮询,交替将请求分配给不同负载。
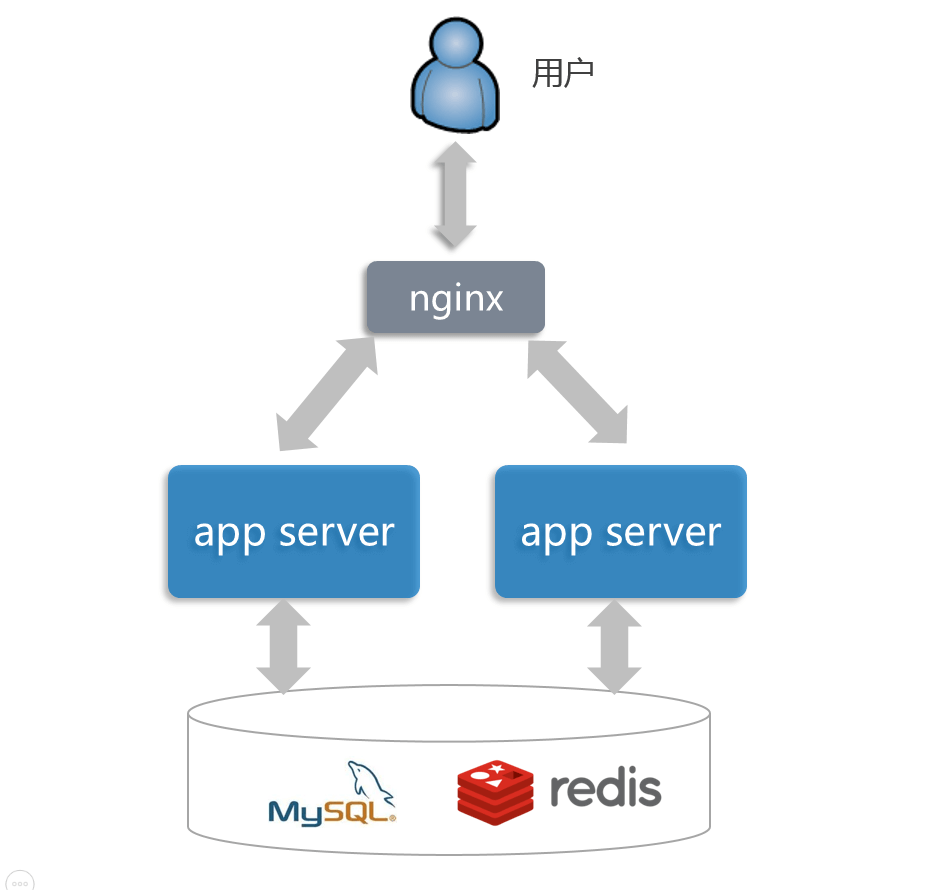
上面是 SaaS 部署的示意图。开发者将 SaaS,也就是图中 app server, 通过 Docker 进行部署。为了实现 app server 高可用,在部署时,PaaS 平台会自动实例化 SaaS 两次,保证两个 Docker 实例同时提供服务。在 app server 的前端,通过 Nginx 做负载均衡,分发用户请求,采用的是正是轮询策略。
应该来说,定位十分准确了,接下来就是如何保证两个实例都进行了索引重建。但就是这个问题花费了不少时间。
2.1 Django Once 代码
在 StackOverFlow 上,找到两种方法实现 Django 在启动时,仅执行一次的功能:
- 利用顶层的 urls.py
urls.py 模块仅会被导入并执行一次。
| |
- 利用 Django App 的 apps.py
apps.py 文件可以配置一些 Django App 自定义的初始操作。
| |
| |
在 one_time_startup() 函数中,实现索引重建的功能。
按照部署逻辑分析,PaaS 平台实例化 app server 时,每个实例都会重建索引,搜索功能可用性应该为 100% ,同时在本地验证搜索功能正常。
但是,实际上线之后,搜索服务并不可用。在部署日志里面,也没有重建索引的日志出现。似乎是 PaaS 平台禁止了在启动实例时,执行内置的一些命令。
2.2 Django URL 访问重建索引
在实例 app server 时,不能重建索引文件,那么直接调用接口呢?
| |
| |
于是,写了一个 url 接口,访问时,执行索引重建命令。在 SaaS 发布上线之后,连续访问两次,分别在两个实例更新索引。
但这种方式,操作难度较大,不能保证两次访问之间,没有其他人访问。
由于使用容器部署,每次部署时,之前部署的本地数据都会被销毁掉。因此,每次部署后都是全新的,只需要将重建索引的代码逻辑放在首页访问的 views 中,在执行重建索引之前添加一个判断。
| |
按照分析,到这步,如果实例中没有索引文件,就重建;如果实例中有索引文件,则跳过重建。两实例中应该都有索引文件,搜索服务的可用性应该是 100% 。然而,并没有!
为了节约 CPU 和内存资源,两台服务器上有数百个 app server 实例。每次重建索引都需要接近 20 秒的时间。
在这 20 秒的时间内,如果有其他请求,因为索引正在创建,检测不到索引文件,又会触发一次重建索引。测试多次,发现搜索功能的可用性依然不是 100%,出现了一个比较奇怪的现象,有时可用,有时不可用,有时还会 500。初步怀疑是,由于连续触发重建索引,消耗大量服务资源出现服务不可以 500,同时,重建索引之前清除了索引,导致正在重建索引的实例搜索服务不可用。
2.3 使用第三方服务
对于一个服务,有时可用,有时不可用,发布起来还特别繁琐易错,显然是不可接受的。于是,使用了 NFS 服务,可以看做是一个第三方的挂载目录服务。在实例化 app server 之后,将本地独享的 RES 目录挂载到 app server 实例容器中的 RES 目录上。最棒的是全部实例共享 RES 目录。
配置非常简单,将 Haystack 的索引目录配置在 RES 目录中:
| |
然后,在通过 URL 访问,执行索引重建命令:
| |
| |
2.4 小节
对于本地正常,但线上不能正常提供服务的异常定位,通常问题在部署上。
了解部署流程和逻辑,对于 SaaS 开发十分重要,特别是依赖 PaaS 进行应用开发、测试、部署的人员。
上面的例子,实际上是一个高可用与高一致性的矛盾。高可用意味着需要多个服务实例,而高一致性需要全部的服务实例数据一致。对于这类矛盾,解决办法就是将数据服务独立出来,上面的例子是通过挂载 NFS 服务来实现。
尽量使用第三方服务,在 SaaS 中不要保持状态。
3. 无状态
无状态是高并发设计的原则之一。如果服务实例不在本地存储持久化的数据,并且多个实例对于同一请求响应的结果是完全一致的,那么称这个服务是无状态的。
一个无状态的服务,很容易的对其进行水平扩展。通过新增更多的实例,可以显著的提高服务的并发性能。
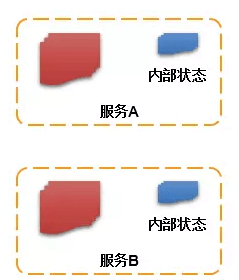
如上图,对于有状态的服务,每个服务内部维护一个状态。
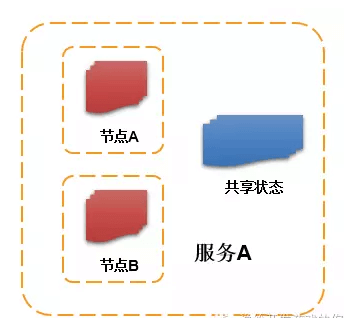
而无状态服务只是把状态从服务中独立出来,共享状态。如上图,节点 A 与节点 B 提供相同的应用服务,同时共享状态。从而实现应用服务的生命周期与状态的生命周期解耦。如果状态服务,也就是数据服务高可用,那么所有的应用服务也都是高可用的。
