1. 不断尝试落地 AI 应用端
基于对运维的认知,我开发了一个开源的运维工具 https://github.com/shaowenchen/ops 。
Ops 工具将运维操作划分为脚本执行、文件分发两类,而运维对象主机和 Kubernetes 集群分别都实现了这两种运维操作。
Ops 对外提供的能力有,Ops Cli 命令行终端,Ops Server 服务端 API 接口,Ops Controller 集群端资源管理,还带有一个简易的 UI 界面,
虽然半年前开发了 Ops Copilot,但其并没有发挥出 Ops 项目的能力,非常的独立,仅仅只是对接上了 LLM,能够提供一些对话、在本地自动执行脚本的能力而已。希望后面有机会借助这次 AI Agent 的技术路线重写 Ops Copilot。
近期主要的工作目标就是基于 Ops 开发一个 AI Agent,自动化地完成一些运维操作。
2. 找到一个可迭代的 AI Agent 技术路线很重要
AI Agent 是 AI 能够与物理世界直接进行交互的重要能力,是真正能够提高生产力,将人类从重复、机械的工作中解脱出来的关键技术。
AI Agent 很美好,但这是站在技术消费者的角度。如果站在 AI Agent 开发者的角度,这件事聊起来就没那么轻松了:
- 一个强烈的需求,最好能与工作内容匹配,能驱动你去开发 AI Agent
- 打磨 AI Agent 的场景,需要大量的使用场景打磨,不断优化实现
- 可迭代的技术路线
1 和 2 得看岗位的基本面,是否支持你去开发 AI Agent。3 是自己可控的,本篇也会着重介绍可迭代的 AI Agent 技术路线。
我们在团队中引入新技术,从来都不会是一蹴而就,始终伴随着阶段性的汇报、阶段性的成果,风险的控制等。即使,你有好的想法和执行力,互联网团队也很难容忍太长时间的人力投入,而看不到任何效果。
互联网产品的开发模式已经接受了敏捷开发的思路,需要不断地做出可用的产品,进行交付,拿到反馈,继续迭代。
3. 什么是服务化的 AI Agent
服务化的 AI Agent 是我造的一个词,下面介绍一下这个词。
3.1 AI Agent 与 Copilot 的区别
AI Agent 强调的是具有自主性,能够主动解决问题;而 Copilot 强调的是辅助、提供建议,需要人的引导。
通过定位事项的主导者,可以很快区分两者。如果事项是程序主导负责,那么就是 AI Agent; 如果事项是人主导负责,那么就是 Copilot。
3.2 服务化的 AI Agent
通常,大家聊的 AI Agent 是本地化的,也就是需要在被操作的设备上执行,甚至在必要时 AI Agent 能在本地部署 LLM 服务。
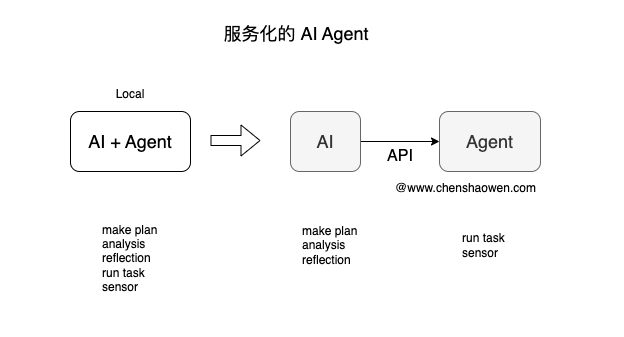
如上图,服务化的 Agent 是以 API 的形式提供任务执行、环境感知的能力。
比如,AI 端生成的 Python 脚本,需要调用 Agent 的 API 才能得到执行,然后返回执行结果。同样,如果需要获取 AI 当前的环境信息,也需要调用 Agent API 才能得到。
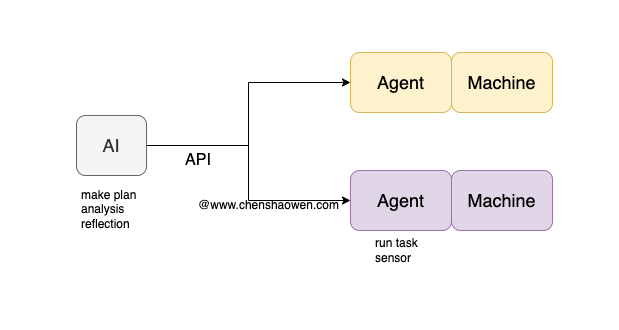
当然你也可以采用多 Agent 的方式,如上图,每个 Agent 对接各自接管的操作对象,将环境的感知和执行能力保留在被操作的设备上。
服务化的 AI Agent 具有以下优势:
- 职责分离,Agent 只负责执行、感知,AI 只负责分析、聚合
- 执行环境更加灵活,可以基于资源、安全等因素配置不同的执行环境,比如集群操作的 Agent、GPU 操作的 Agent、云资源操作的 Agent
- 更容易对接已有的系统,可以每个系统开发一个 SideCar Agent 对接到 AI,而不是一个本地化的 AI Agent 集成全部系统
3.3 Ops 就是一个服务化的 Agent 端
Ops Server 的定位是通过 API 接口,能够执行 Ops 中内置的 Task 任务。这些 Task 任务都是一些敏感的运维操作。
通过 Ops Server 的 API 接口,能够具备以下能力:
感知:
- Host 主机列表
- Kubernetes 集群信息
- Host 内部能通过 Shell 获取的信息
- Kubernetes 集群能通过 kubectl 获取的信息,以及各个节点能通过 Shell 获取的信息
执行:
- Host 主机操作
- Kubernetes 集群 kubectl 操作,以及各个节点 Shell 操作
这些能力已经足够让 AI 完成大部分的运维任务了。
4 开始写一个服务化的 AI Agent
4.1 抽象两个对象
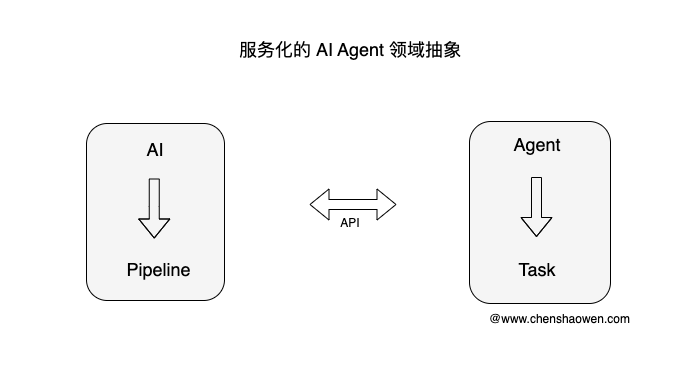
如上图,服务化的 AI Agent 中
- 驱动 AI 的对象是 Pipeline
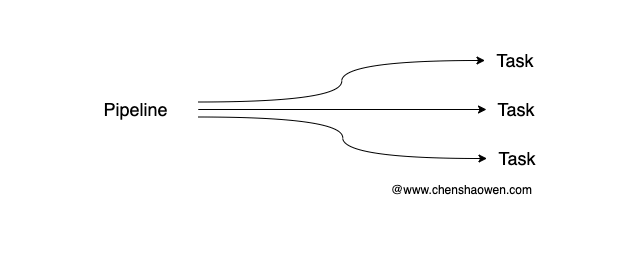
AI 端的一个 Pipeline 对应 Agent 端的多个 Task,这些 Task 通过一定顺序的排列组合、条件控制加上变量值,实现 Pipeline 的任务目标。
- 驱动 Agent 的对象是 Task
在 Ops 中,我已经提供了一个 Task CRD 对象,内置了大量 Shell 脚本,用于收敛、复用运维的基本操作。
4.2 使用 Task 封装 Agent 的基本操作
这是我们线上使用的部分运维 Task :
| |
增加新的 Task 只需要编写一个 Yaml 文件,开发一个新的 Task 非常容易。
4.3 使用 Pipeline 对接业务场景
由于 Ops 中并没有抽象 Pipeline 的概念,我在 AI 端定义了 Pipeline 对象。
针对每一个具体的场景,都可以编写一个 Pipeline,下面是一个示例:
| |
这里使用了两个 Task
- inspect-clusterip - 查询 cluster ip 详情,通过 API 调用,任务会下发到 Agent 执行
- app-summary - 通过 LLM 总结输出的信息。
有两类 Task: 一种是实时从 Agent 获取的; 一种是 AI 端自定义的 Task,这是为了封装一些与 Ops 无关的任务,当然也可以再开发一个 Agent 执行此类任务。
4.4 AI 端的开发
通常 AI Agent 是一个死循环的进程,不断地处理预期的数据,然后制定计划、执行计划、反省及再次制定计划,周而复始,直到解决问题。
但这种处理方式比较耗 Token,而且项目开发的早期,Prompt、Task、环境感知都没有准备完善,很难有好的效果。因此,主要分为以下几个迭代阶段:
- 实现预设场景的 AI Agent 辅助能力
针对特定场景,具有固定的上下文,确定的输入,我们开发 AI Agent 的目标会非常明确,容易拿到好的结果。同时,也是为了我们能够沉淀相关的 Task 能力,调试 Prompt 。
- 通过向量库、周边系统,召回关键信息
可以预见的是,随着场景接入数量的剧增,每次需要给 LLM 提供的 Pipeline 描述、集群、主机信息会越来越多,会遇到以下问题:
- 超长的文本会降低识别执行哪条 Pipeline 的准确性
- 缺少足够上下文及反馈,导致 AI Agent 无法解决问题、验证问题是否解决
此时就需要与输入更相关、更多的数据,将 Pipeline 的相关信息、执行结果、依赖的周边系统信息召回。让 AI Agent 根据这些信息,自主的执行 Pipeline,拿到结果,继续执行直至达到终止条件。
- 自主唤醒
不再需要人工 at 唤醒,而是 AI Agent 能自动捕获关键信息,自动唤醒。从技术上这一点并不难,难点只在于,AI Agent 是否已经准备好,能够适应全量的场景。
通过 at 唤醒只能覆盖一部分场景,但如果让 AI Agent 自动唤醒,需要考虑的细节、边界,就会比较多。
- AI 自主编写 Pipeline
AI Agent 通过输入,自主检索向量库,拿到相关的 Task 和上下文信息,编写出 Pipeline、甚至新的 Task。此时,AI Agent 才达到了理想状态。
4.5 看看我实现的效果
目前按照上面的思路,我完成到 1 的阶段,但 2、3、4 在技术上是可行,需要时间迭代。
- 重启一个 Pod
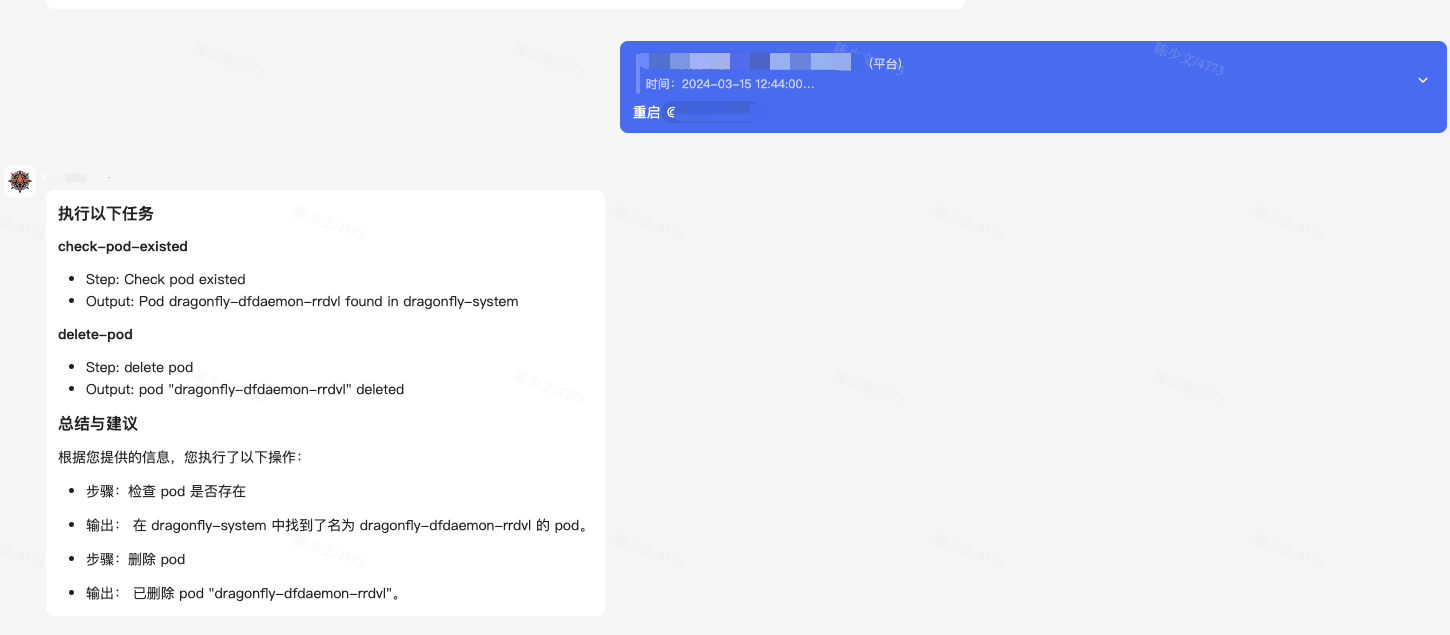
- 查看一个告警信息的详情
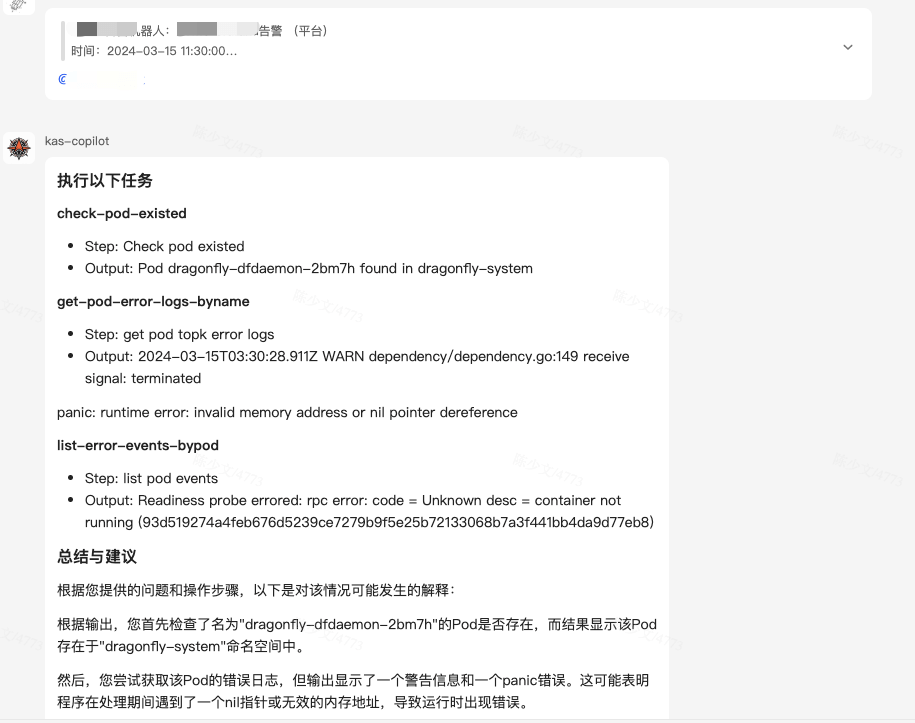
基本实现了 Pipeline 与 Task 的对接,能够处理一些基本的运维场景,值得注意的是,新的场景接入成本特别低。只需要复用或者新增 Task,注册到 allTasks,编排 Pipeline 注册到 allPipelines 就能添加新的场景。
5. 对齐是开发 AI Agent 的巨大挑战
可能不止是开发 AI Agent,所有 LLM 的应用场景都会遇到对齐的问题。
5.1 怎么有效提取关键信息
AI 端在运行 Pipeline 时,需要命中 Pipeline 并提取相关运行参数。为此需要在 Pipeline 中:
- 详细描述 Pipeline 的用途
| |
Desc 能够让 LLM 准确识别 Pipeline 的用途。
- 详细描述变量含义、格式特征等
| |
变量的提取不准是一个常见的问题,需要对依赖的变量进行详细描述。这些描述信息包括,变量的描述、正则表达式、示例值、默认值、是否必填等,特征越多越明显,LLM 越容易做出正确的判断。
为了让 AI 端能够正确识别操作的集群对象,我甚至直接将动态获取的 Cluster 列表提交给了 LLM。
| |
5.2 Retry 依然有效
一个月我写了三、四个版本的 AI Agent。第一个版本 AI 直接对接到 Task,没有抽象 Pipeline,效果还行,但经常会出现这样的状况。
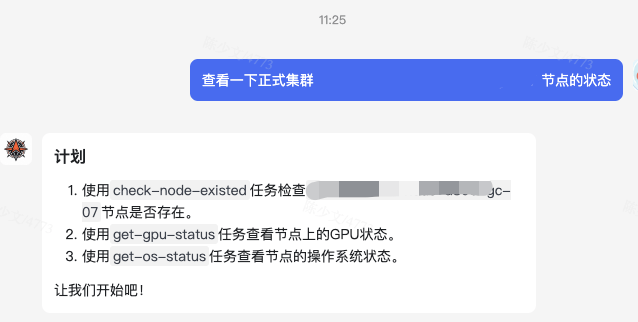
如上图,LLM 有时并不会输出我想要的 Json 格式数据,而是直接输出了一个 Plan 计划。而符合预期的响应应该是 LLM 返回一段 Json 数据,然后 Agent 执行这些 Task,返回给用户最终的结果。如下图是一个符合预期的示例:

因此 Retry 重试依然是有效解决对齐问题的关键方法之一。当 LLM 不理解你的意图时,你只需要重试一次。当 LLM 不能有效提取关键信息,你只需要重试一次。当 LLM 无法给出预期的结果时,你只需要重试一次。
在执行 Pipeline 时,程序出现了非预期的状态,重试基本都能立即改善最终的响应结果。
5.3 Reflection\Reward 能提高准确率
同样是 Retry 循环,如果能加上一点反馈或者奖励,也能提高 LLM 与场景意图的对齐能力。
在 https://blog.langchain.dev/reflection-agents/ 中有相关的描述,如下图:
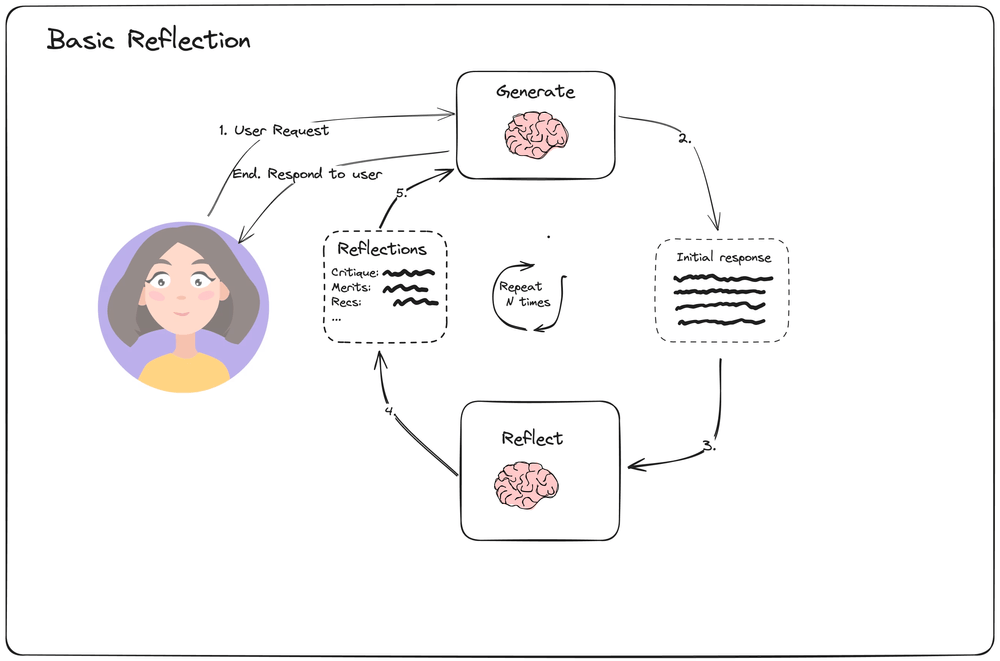
我们只需要检查 Pipeline 的状态是否符合预期,提出自己的要求、对某些关键状态进行检查,给出评价,再次给 LLM 重试即可。
5.4 数据的预选
前面我已经提到,当接入大量场景之后,必然会触发 LLM 单词处理的 Token 上限,同时,长文本也会削弱 LLM 的信息提取能力。
进行数据的预选,能够避免这些问题,将问题缩小在输入相关的信息上。
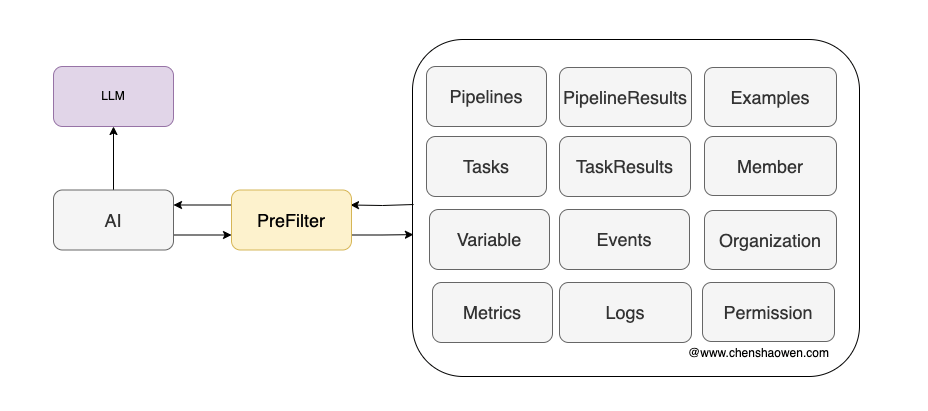
如上图,需要预选的数据类型可能会有很多,比如:
- 执行模板,Pipeline 、Task 模板
- 上下文,当前输入相关的领域信息,运维相关的就是 Metrics、Logs、Events 等信息,当然也可以通过 Task 实时查询
- 团队人员相关的,比如应用的负责人
- 权限信息,当执行 Permission Task 时,需要校验用户的权限
- 知识库,这里就需要用到向量数据库进行召回
- 一些示例、成功的 Case,以供 LLM 做 few-shot learning
6. 总结
本篇主要是我在最近开发 AI Agent 应用的一些总结,主要内容如下:
在团队中落地 AI Agent 应用,找到可迭代的技术路线很重要,有利于汇报和阶段性的展示成果。
介绍了一种服务化 AI Agent 的设计思路,将 AI Agent 拆分为 AI 端负责分析,Agent 端负责执行,他两者通过 API 交互。服务化的 AI Agent 有利于现有系统的集成,避免 AI Agent 集成全部系统。
介绍了一个开发服务化 AI Agent 的迭代思路,AI 端使用 Pipeline 对象,Agent 端使用 Task 对象,首先通过内置的 Pipeline 对齐具体场景,通过向量检索提升大规模实践下的精准度,然后让 AI Agent 自主唤醒接入全量场景,最后让 LLM 自主编排 Pipeline 完成任务。
介绍了几种解决在开发 AI Agent 应用时对齐问题的方法,包括准确的功能、字段描述,Retry 机制,Reflection\Reward 机制,数据预选。
纸上得来终觉浅,绝知此事要躬行。只有当自己真正动手写 AI Agent 解决实际问题时,才发现原来有这么多坑,谨以此文记录。
