监控系统的难点在于,存储大容量时序数据,提供高性能的查询能力;告警系统的难点在于,设计高效的告警引擎,实现灵活的告警升级机制。最近一直在跟踪监控告警系统,本篇主要是整理监控告警相关的一些概念、组件,调研方案。
1. 监控告警系统的组成
对于监控告警的定义,每个人都会有一些自己的理解。我的理解是: 监控是将发生的事情记录下来,以供事前事后分析;告警是当非预期的事情发生时,能够及时告知。
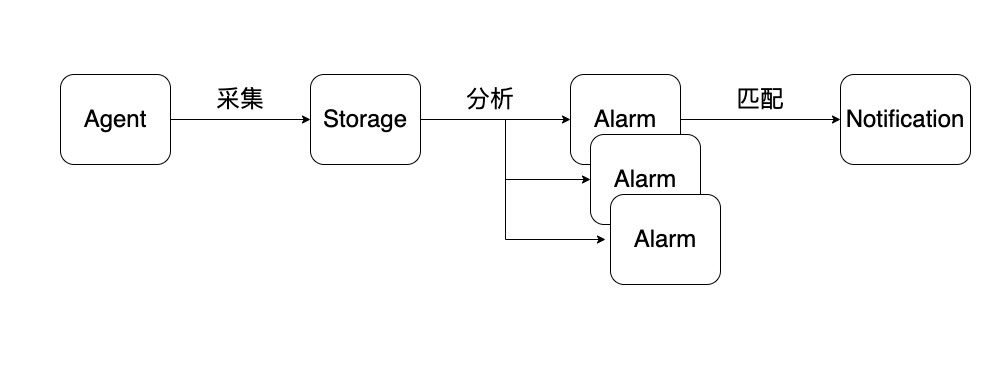
如上图,一个监控告警系统会包含如下几个部分:
Agent - 负责采集,并将关注的指标数据上报
Storage - 负责存储 Agent 上报的数据
Alarm - 负责检测上报的数据是否达到预设的阈值
Notification - 负责将告警发送给指定的接收人
2. 采集
2.1 采集的数据格式
不同于传统的关系型数据库,监控指标的数据实际上是基于时间的抽样,适合使用时序数据库进行存储。目前主流的时序数据库,大多数都是采用 Metric 加 Tag 的方式,来描述一条监控指标,Tag 的作用是标记指标的维度信息。下面是一条监控数据:
api_http_requests_total{path="/home",status=200,method="GET",instance="10.10.12.11"}
其中,时序的名字为 api_http_requests_total,标签为 path、status、method 和 instance,时序名字和标签共同决定了一个时序。
因此,我们才可以根据 status Tag 统计状态码的分布,根据 method Tag 统计请求方法的比例。
2.2 采集组件 Exporter
Exporter 通过 http 服务暴露指标数据给采集方抓取,比如暴露给 Pormetheus。Exporter 不会存储历史数据,只会等待采集方抓取时,提供最近一次的数据。
在开源社区中,已经有各种主机、中间的 Exporter 可供使用,非常方便。
2.3 AllInOne 的 Exporter - Telegraf
使用 Exporter 让人烦恼的地方在于,主机有一个 Exporter、MySQL 有一个 Exporter,如果运维组件很多,Exporter 的维护成本很高。
Telegraf 采用了类似 Logstash 的 Pipeline 方式,使用 input、output 以及 processor 插件组装采集能力。因此,我们只需要使用一个 Telegraf + 多种配置文件就可以替代多种 Exporter,大大降低了维护的成本。
但另一方面,由于 Telegraf 包含的采集器太多,会导致可执行文件过大。因此,有时我们也会裁剪 Telegraf,去掉用不上的部分,以维持可执行文件足够小。
2.4 Pushgateway 补充推送场景
Exporter 只是提供 http 接口,被动等待采集。但是有些场景下,需要主动推送指标数据,比如短生命周期的 Job 任务,等不到采集方抓取就被销毁了。这时,Pushgateway 就能够接受 Job 主动推送的监控数据,再等待采集方的抓取。
另外一个场景是,如果所有 Exporter 都在采集方配置采集端点,会导致采集方配置难以维护。因此,也可以使用 Pushgateway 提前将数据聚合,再提供给采集方。这样可以减少采集方维护采集端点的成本。
还有一个场景是,Exporter 与采集方的网络不可靠时,需要通过 Pushgateway 进行中转。
3. 存储
3.1 时序数据库的特征
监控数据的特征是与时间序列强相关,因此需要使用的是时序数据库。市面上已经有大量开源的产品可以使用,InfluxDB、OpenTSDB、M3DB 等,这些时序数据库碰到的核心问题是 垂直写,水平读 。

如上图所示,我们在采集指标时,每次采集的是某一个时刻的数据,但是在查询时却又基于某一个 Metric 指标进行统计,基于 Tag 进行过滤查询。这种使用方式,给时序数据库的设计和实现带来了挑战。既要能快速存储大量垂直指标数据,又要能够快速查询水平数据。
3.2 Prometheus
Prometheus 是前 Google 工程师在 Soundcloud 开源的监控告警项目。目前,大部分公司都会采用 Pormetheus 作为监控告警工具。
Prometheus 的特点是:既有数据存储,也有告警引擎。因此,只需要部署一套 Pormetheus 就可以开箱即用,满足大部分的监控场景。
Prometheus 的问题是:服务单点,使用文件配置规则。当单点的 Prometheus 重启或抓取 Exporter 数据故障时,都会导致监控数据缺失。因此,生产环境下,有时也会采用两套 Prometheus 同时抓取 Exporter 指标数据的方案。
3.3 为啥要远端存储
Prometheus 为了降低自身的复杂度,使用了本地存储,足以满足大部分用户规模的监控场景,但无法满足对长期数据的查询需求。因此,在业务规模较大时,我们会将 Prometheus 的本地数据作为临时数据,而将长期数据转存到远端。
最终,针对近期数据的告警查询,使用的是 Prometheus; 而历史数据的统计查询,使用的是远端存储。这里介绍三种远端存储方案:
- InfluxDB
InfluxDB 在时序数据库排名中,长期占据第一。InfluxDB 的集群模式需要收费,单例模式源码开源。我们可以将 Prometheus 的 remote write 到 InfluxDB,当 Grafana 从 Prometheus 进行长期查询时,使用 InfluxQL 查询 InfluxDB,进行短期查询时,使用 PromQL 查询 Prometheus。
- VictoriaMetrics
VictoriaMetrics 也分为单机版和集群版。VictoriaMetrics 并不是 100 % 兼容 PromQL 查询语句。如果没有用到告警,单机版的 VictoriaMetrics 可以直接用于替换 Prometheus,也可以作为 Prometheus 的远端存储使用。VictoriaMetrics 也提供了集群模式,包含 vmagent、vmstorage、vminsert、vmselect、vmalert 组件,实现了一整套高可用、存储可扩展的监控告警方案。
- Thanos
Thanos 的定位是监控终结者,得到社区大力推荐。Thanos 包含 Querier、Slidercar、Store、Compactor 组件,通过在 Prometheus 上挂载 Sidecar 上报数据并提供查询能力。Thanos 会将监控数据存储到 S3,同时 Compator 还会对数据进行采样。这样的好处是,在查询长期数据时,可以先查 S3 采样的数据展示结果,而不是读取全量数据。
4. 分析
当指标上报、数据进入时序数据库之后,我们就需要不断地查询分析,指标是否符合预期,或者查看长期数据。
数据检测的过程就是不断地调用接口查询的过程。如果用代码实现,就是一个循环。但其中有很多的细节需要考虑:
- nodata
没有数据的原因可能是服务没有上报数据,也有可能是上报链路异常,还可能是查询时异常。这种情况下,如何处理?常见的有两种处理方式:1,nodata 上报特殊数值;2,单独实现 nodata 的检测。
- 大量检测
当配置的每分钟检测规则达到一定数量级时,单个时序数据库扛不住。这里就会衍生出一些优化的方案,比如使用集群分担查询、在检测时刻 BIAS 几秒错峰等。还有一种方案是,使用 Redis 等高性能数据库临时存储短期指标数据,用于告警检测。
5. 告警
分析阶段会产生大量告警事件,这些事件如果直接推送给用户,将会产生大量垃圾信息。告警模块的目的是为了提高通知的价值密度,让用户能够准确高效地获知线上故障。
- 告警规则的管理
告警规则提供了分析阶段需要的查询语句。怎样高效地管理这些告警规则,是告警系统需要解决的问题之一。
- 告警实例的管理
在监控数据达到告警规则阈值时,就会产生一个告警实例。我们需要对告警实例进行管理。告警实例状态会发生流转,正在告警、恢复、未处理。
- Alertmanager
社区中很多方案都会使用 Prometheus + Alertmanager 的告警组合,使用 helm 部署 Prometheus 时,也可以很方便地部署全套方案。
Prometheus 提供的告警引擎,在检测到异常时,会将告警推送给 Alertmanager 。Alertmanager 会根据路由配置,将告警发送给指定的接收人。Altermanager 也是采用文件配置规则。
6. 参考
- https://toutiao.io/posts/lha0c8/preview
- https://www.163.com/dy/article/FCEQU6210511CUTF.html
- https://segmentfault.com/a/1190000040480428
- https://zyun.360.cn/blog/?p=1536
- https://github.com/prometheus/cloudwatch_exporter
- https://github.com/huaweicloud/cloudeye-exporter
- https://n9e.github.io/quickstart/standalone/
- http://mysql.taobao.org/monthly/2018/02/02/
- https://zhuanlan.zhihu.com/p/155719693
