1. 消息队列的适用场景
1.1 异步处理
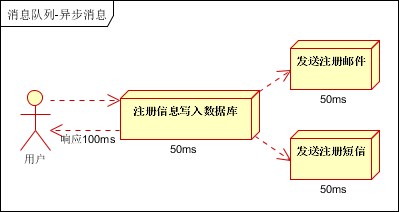
应用场景:用户注册后,需要发注册邮件和注册短信。同步的处理方法,系统的性能(并发量,吞吐量,响应时间)会有瓶颈。
1.2 应用解耦
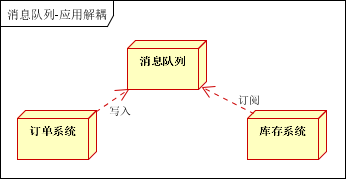
应用场景:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口,应用之间会有强依赖。采用消息队列下单后,订单系统写入消息队列就不再关心其他的后续操作,实现订单系统与库存系统的应用解耦。
1.3 流量削锋
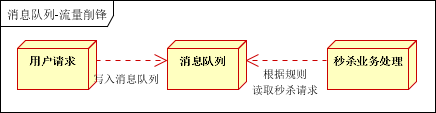
应用场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。采用消息队列后, 用户的请求,服务器接收后,首先写入消息队列,保证的服务的正常。
1.4 消息驱动的系统
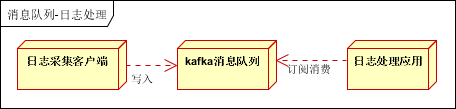
应用场景:在日志处理中,比如 Kafka 的应用,解决大量日志传输的问题
2. 有哪些消息队列
Kafka 是 LinkedIn 开源的分布式发布-订阅消息系统,目前是 Apache 顶级项目。Kafka 主要特点是基于Pull 的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。Kafka 不支持事务,对消息的重复、丢失、错误没有严格要求。内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1) 的复杂度,消息处理的效率很高,适合产生大量数据的互联网服务的数据收集业务
RabbitMQ 是基于 AMQP 协议实现,使用 Erlang 语言开发的开源消息队列系统。AMQP 协议多用于企业系统内,对数据一致性、稳定性和可靠性要求很高的场景。AMQP 的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。RabbitMQ 在吞吐量方面稍逊于 Kafka,d但支持对消息可靠的传递,支持事务,不支持批量的操作。
3. RabbitMQ 与 Celery
Celery 是一个异步的作业队列,没有消息存储功能。它的基本功能是管理分配任务到不同的服务器,并且取得结果。
而 RabbitMQ 是一个消息代理。它的基本功能是接收并转发消息。因此,Celery 通常配合 RabbitMQ 使用,当然也可以使用 Redis、MongoDB 之类。
RabbitMQ 中的一些基本概论:
producing 的意思是发送。一个发送消息的程序叫做 producer。
一个 queue,即队列,相当于一个邮箱,它由 RabbitMQ 管理。尽管消息会在应用和 RabbitMQ 之间流过,但他们只被保存在队列中。队列没有边界限制,你想存多少消息就能存多少。它本质上是一个无限制的缓冲区。一个队列可以接收多个 producer 的消息,也可以被多个 consumer 读取。
consuming的意思类似于接收。一个等待接收消息的程序叫做consumer。在图中我们用一个“C”来表示它。
4. 使用
4.1 安装 RabbitMQ
| |
此时,RabbitMQ 已经启动,但是无法访问 RabbitMQ 提供的管理页面,因为默认没有被开启。
4.2 开启 Web 管理页面
启动 RabbitMQ 后,没法访问 Web 管理页面
第一步,启动管理插件(先启动rabbitmq服务再装插件)
| |
第二步,重启服务
在 Windows 下:
| |
在 Linux 下:
| |
第三步,访问 Web 管理页面
http://127.0.0.1:15672
默认账户密码:guest:guest
4.3 常用命令 RabbitMQ
启动监控管理器:rabbitmq-plugins enable rabbitmq_management
关闭监控管理器:rabbitmq-plugins disable rabbitmq_management
启动 RabbitMQ:rabbitmq-service start
关闭 RabbitMQ:rabbitmq-service stop
查看所有的队列:rabbitmqctl list_queues
清除所有的队列:rabbitmqctl reset
关闭应用:rabbitmqctl stop_app
启动应用:rabbitmqctl start_app
4.4 Celery 应用
使用 pip 安装 celery
| |
第一步,定义任务函数。
创建一个文件 tasks.py
| |
第二步,运行 Celery 任务。
| |
第三步,调用任务
| |
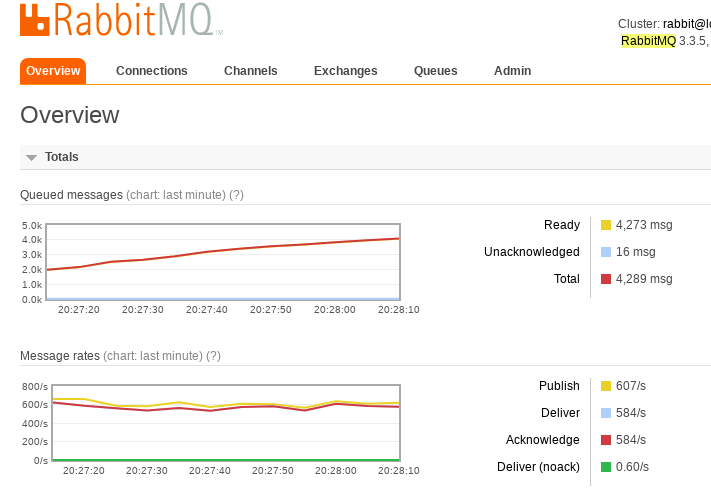
通过 delay 可以实现函数的异步调研。下图是,执行 In [2] 时的处理速度图示,可以看到处理的消息数量在不断增加,处理的速度达到了瓶颈。
5. 高可用
RabbitMQ 模式大概分为以下三种:单一模式、普通模式、镜像模式。
- 单一模式:单机模式
- 普通模式:默认的集群模式。
对于 Queue 来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构。
当消息进入 A 节点的 Queue 后,consumer 从 B 节点拉取时,RabbitMQ 会临时在 A、B 间进行消息传输,把 A 中的消息实体取出并经过 B 发送给consumer。
所以 consumer 应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理 Queue。否则无论 consumer 连 A 或 B,出口总在 A,会产生瓶颈。 - 镜像模式
把需要的队列做成镜像队列,存在于多个节点,属于 RabbitMQ 的高可用 HA 方案。
该模式解决了上述问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在 consumer 取数据时临时拉取。
该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。
