1. 监控的分层
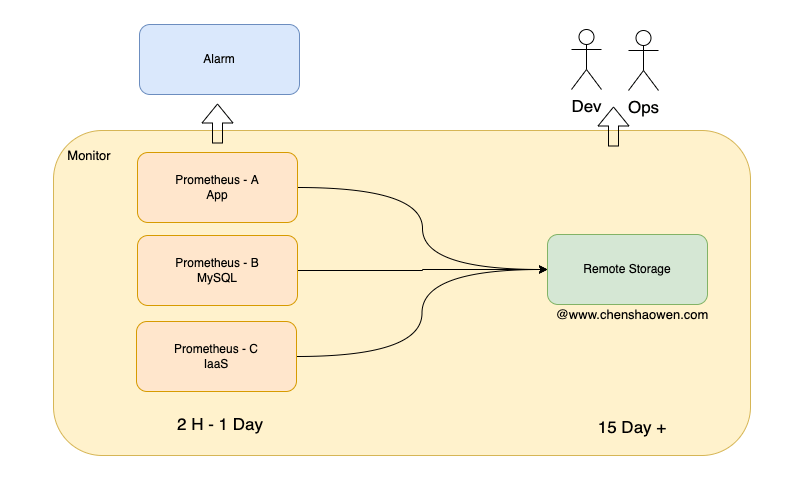
如上图,在建设监控系统时,会采用两种策略:
- 分层监控。IaaS、MySQL 中间件、App 层监控分开的好处是,系统之间具有高可用性、容错性。当 App 层监控无法工作时,IaaS 层监控立马就会体现出来。
- 长短期指标分离。短期指标用来提供给告警系统高频查询近期数据,长期指标用来提供给人查询时间跨度更大的数据集。
这里将其统称为监控的分层策略,只不过一个是以基础设施维度的分层,一个是以时间维度的分层。
2. 现状与选型
目前的状况是: 没有进行监控的长短期分层,共用一套 Prometheus。查询长周期指标时,Prometheus 所在服务器内存、CPU 使用率飙升,甚至导致监控、告警服务不可用。
原因在于两点:
- 查询长周期数据时,Prometheus 会将大量数据载入内存
- Prometheus 载入的不是降采样数据
查询的范围越大,需要的内存就越多。在另外一个生产的方案中,我们采用 VictoriaMetrics 单机版作为远端存储,部署的内存高达 128 GB 。同时,这种方式下还存在丢数据的情况,排查很久之后,才通过参数 honor_timestamps: false 解决。
而 Prometheus Federation 的方式,只是解决了将多个 Prometheus 聚合起来,并没有提供抽样的能力,不能加快长期指标的查询,不适用于当前远端存储的场景。
最后看到 Thanos Compact 组件能够对指标数据进行压缩和降采样,决定尝试使用 Thanos 作为目前多个 Prometheus 远端存储使用。
3. Thanos 的几种部署方式
3.1 基础组件
- Query, 实现了 Prometheus API,对外提供与 Prometheus 一致的查询接口
- Sidecar, 用于连接 Prometheus,提供 Query 查询接口、也可以上报数据
- Store Gateway, 访问放在对象存储的指标数据
- Compact, 压缩采样、清理对象存储中的数据
- Receive, 接收 Prometheus Remote Write 的数据
- Ruler, 配置和管理告警规则
3.2 Receive 模式
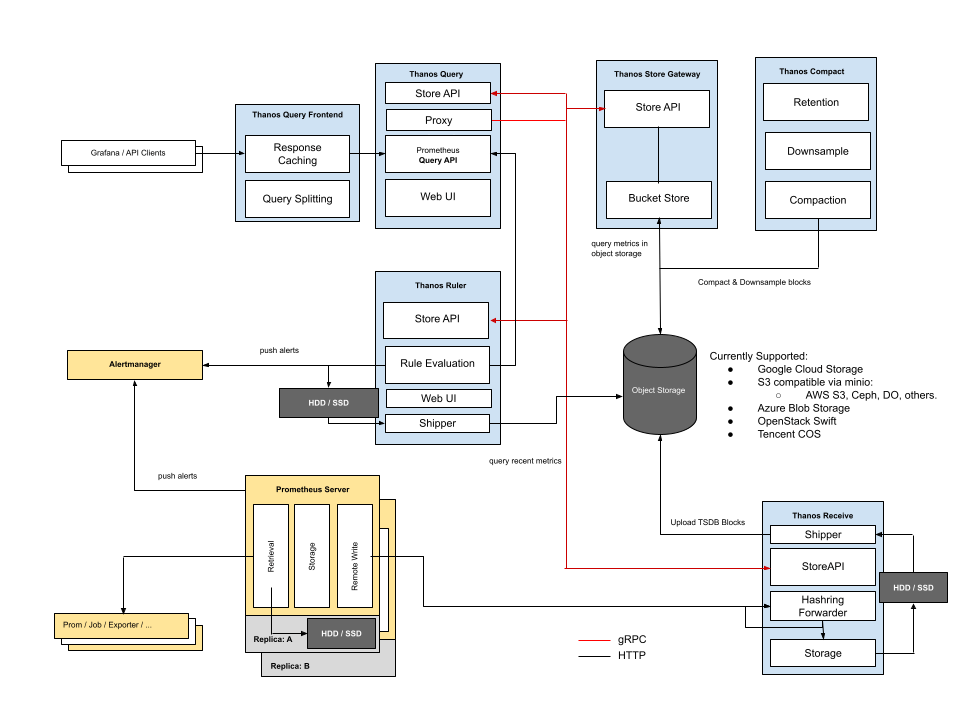
Receive 模式下,需要在每一个 Prometheus 实例中配置 remote write 将数据上传给 Thanos。此时,由于实时数据全部都存储到了 Thanos Receiver,因此不需要 Sidecar 组件即可完成查询。
优势:
- 数据集中
- Prometheus 无状态
- 只需要暴露 Receiver 给 Prometheus 访问
缺点:
- Receiver 承受大量 Prometheus 的 remote write 写入
3.3 Sidecar 模式
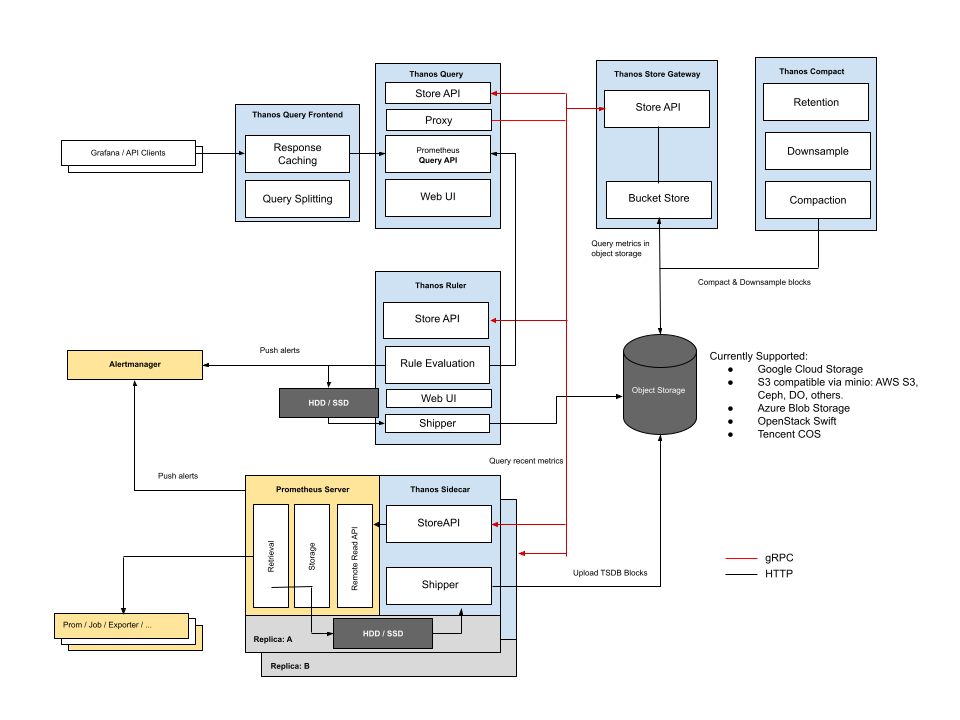
Sidecar 模式下,在每一个 Prometheus 实例旁添加一个 Thanos Sidecar 组件,以此来实现对 Prometheus 的管理。主要有两个功能:
- 接受 Query 组件的查询请求。在 Thanos 查询短期数据时,请求会转到 Sidecar。
- 上传 Prometheus 的短期指标数据。默认每两个小时,创建一个块,上传到对象存储。
优势:
- 集成容易,不需要修改原有配置
缺点:
- 近期数据需要 Query 与 Sidecar 之间网络请求完成,会增加额外耗时
- 需要 Store Gateway 能访问每个 Prometheus 实例
4. 部署 Thanos
4.1 部署一个 Minio
请参考文档: Jenkins 中的构建产物与缓存
安装完成之后,请根据文档中的配置进行测试,确保 Minio 服务正常工作。
4.2 在 Minio 上创建一个名为 thanos 的 Bucket
如下图:
4.3 检查 Prometheus 版本符合 Thanos 要求
目前 Thanos 要求 Prometheus 版本最好不低于 v2.13。
4.4 部署 Thanos
- 确保 Kubernetes 集群上有默认的存储可用
| |
- 新建一个命名空间 thanos
| |
- 部署 Thanos
| |
修改 demo/objectstorage.yaml 文件中的 Minio 访问地址。然后创建 Thanos 相关负载:
| |
- 查看相关负载
| |
部署 Thanos 消耗的资源很少。
4.5 访问 Thanos Query
- 查看 Thanos 相关服务的端口
| |
- 访问 Thanos Query 页面
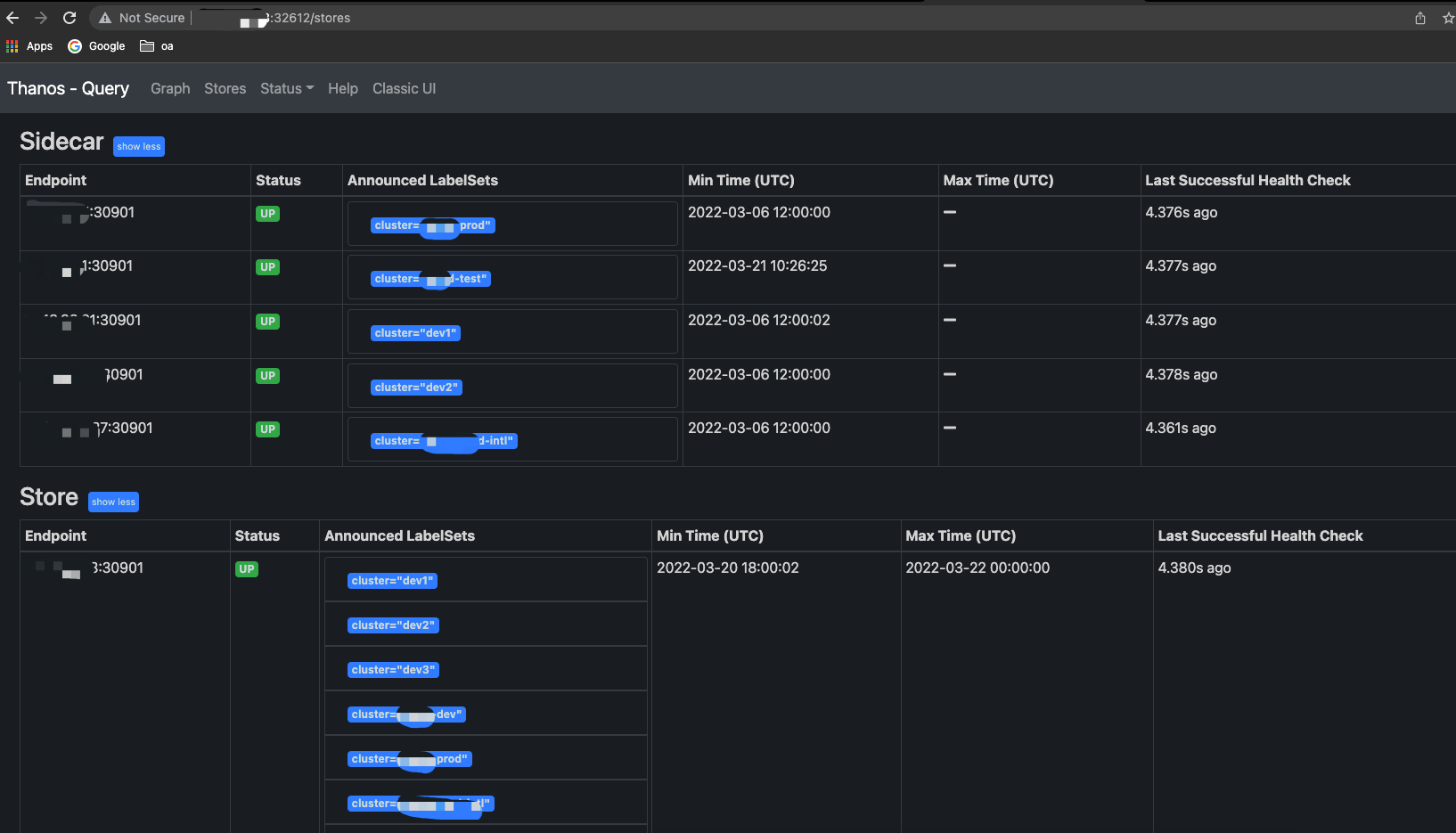
thanos-query 在 9090 端口提供 http 访问入口,因此这里通过主机 IP:32612 端口访问 Query 组件提供的页面。
5. 给 Prometheus 添加 Thanos Sidecar
Sidecar 模式对 Thanos 配置要求更低,而 Receiver 模式需要不停地接受来自众多 Prometheus 的 Remote Write,这里出于成本考虑选择 Sidecar 模式。
5.1 在 Prometheus 所在命名空间新增 S3 访问凭证
| |
这里直接使用的是管理员账户,如果是生产上,应该单独创建一个账户用于 Thanos 对 Minio 的使用。
5.2 给 Prometheus 添加额外的 Label 标记实例
通过在 Prometheus 中添加 external_labels 可以给每个 Prometheus 实例全局添加一个额外的标签,用于唯一标记一个实例。
- 编辑配置文件
| |
- 添加如下内容
| |
这里添加了一个名为 cluster=dev 的标签。所有该 Prometheus 实例上报的指标都会带上此标签,方便查询过滤。
5.3 修改 Prometheus 启动参数关闭压缩
- 编辑 Prometheus 部署文件
有的是用 Deployment,有的是用 StatefulSet 部署,都需要修改 Prometheus 的启动参数
| |
- 修改 tsdb 存储块最大、最小值相等
| |
storage.tsdb.min-block-duration 和 storage.tsdb.max-block-duration 相等,才能保障 Prometheus 关闭了本地压缩,避免压缩时,Thanos 上传失败。
5.4 给 Prometheus 添加 Thanos Sidecar
- 编辑 Prometheus 部署文件
| |
- 新增如下容器
| |
- 新增挂载秘钥
| |
- 重启 Prometheus
滚动升级会遇到如下错误,因为上一个 Prometheus Pod 没有释放文件目录导致。
| |
因此需要先将副本数设置为 0,在将其设置为 1,重启 Prometheus。
| |
5.5 在 Prometheus Sidecar 添加 Grpc 远程访问端口
- 编辑 Prometheus Service 配置
| |
- 新增一个 Service 端口暴露 Grpc 服务给 Thanos Store Gateway
| |
5.6 在 Thanos Query 添加 Store Grpc 地址
最后还需要在 Thanos Store Gateway 中添加上面 Prometheus Sidecar 的 Grpc 地址。
- 编辑 Thanos Query
| |
- 在启动参数中添加
--store=0.0.0.0:30901
| |
这里的 0.0.0.0:30901 需要替换为上面 Prometheus Sidecar 暴露的 Grpc 访问入口。这样,Thanos Query 提供查询能力时,短期数据就会调用 Grpc 查询,而不是查询对象存储中的数据。
此时,在上面提到 Thanos Query 页面以及可以看到新增的 0.0.0.0:30901 这个 Endpoint 记录,状态应该是 Up。
5.7 在 Minio 中查看同步的数据
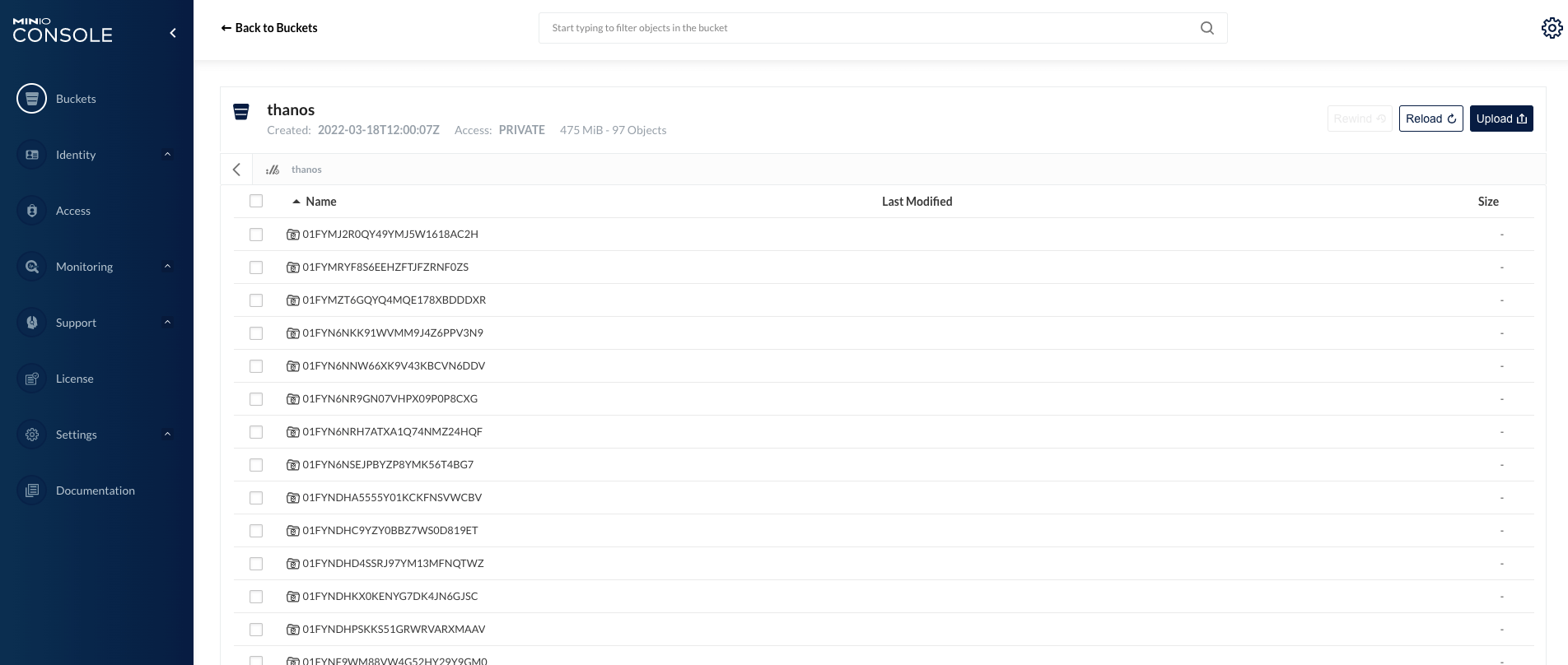
一共添加了 6 个集群,每个集群大约 40 个 Pod,半天时间大约用了 2.1 GB 存储、303 个对象。
6. Grafana 配置
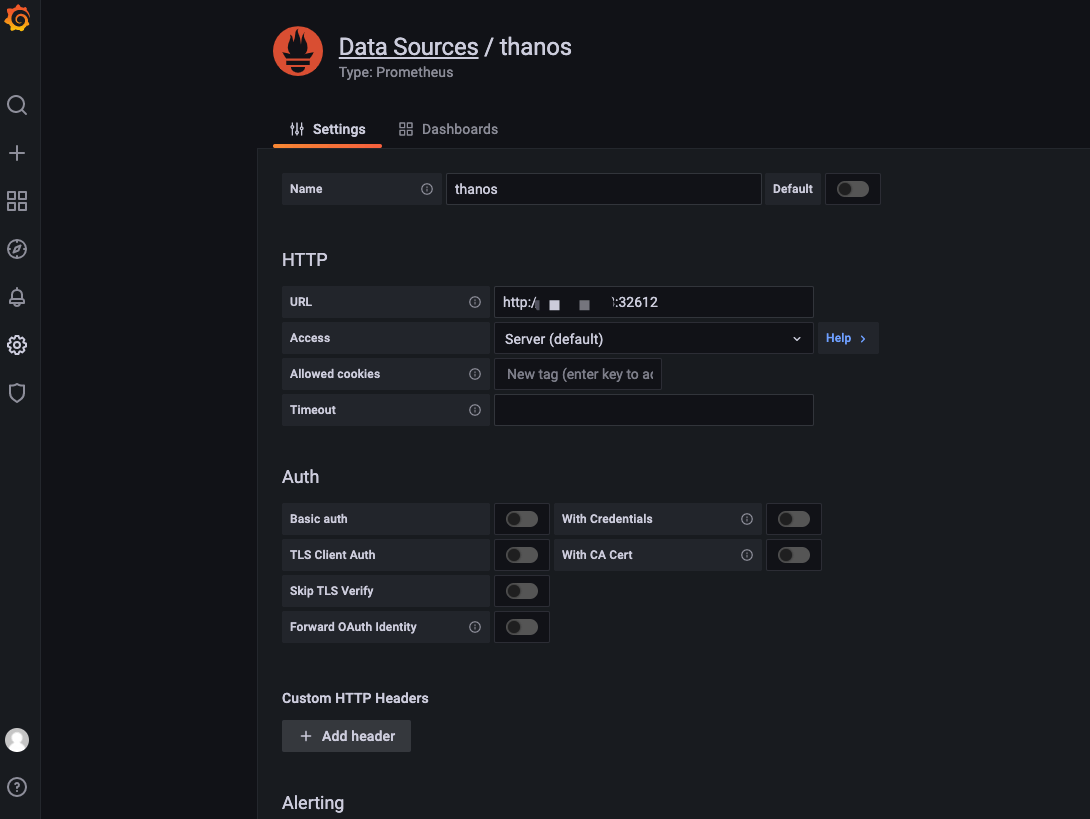
6.1 添加数据源
在 Grafana 添加 Thanos Query 数据源的方式和添加 Prometheus 一样。如下图:
6.2 修改 Grafana 面板适配 cluster 标签过滤
这里在基于 Kubernetes 集群查看的面板,稍微进行修改。
- 添加 cluster 过滤的变量
在上面,我在每一个 Prometheus 中都添加了一个全局的 external_labels,通过 cluster 字段来区分不同的集群。
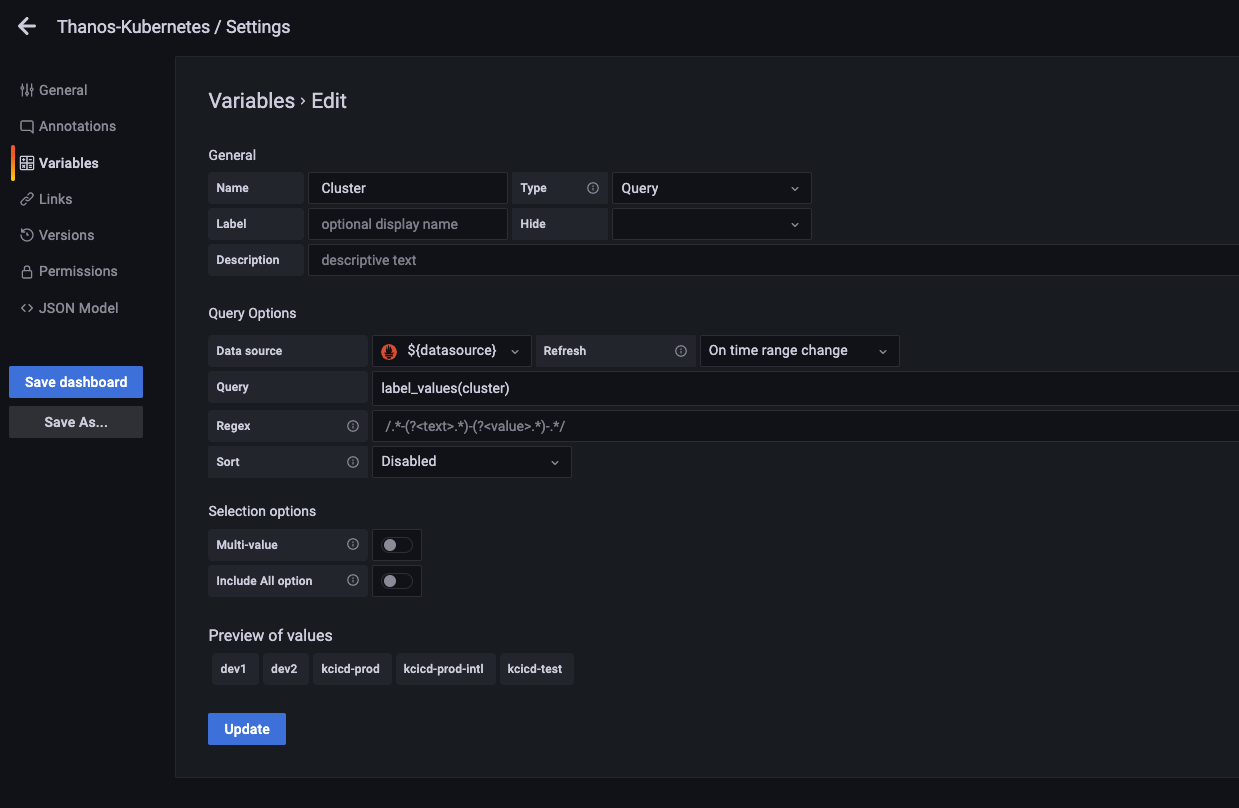
如上图,在面板中添加一个 Cluster 变量,使用指标中的 cluster 标签进行过滤。
- 编辑每个视图的过滤查询条件
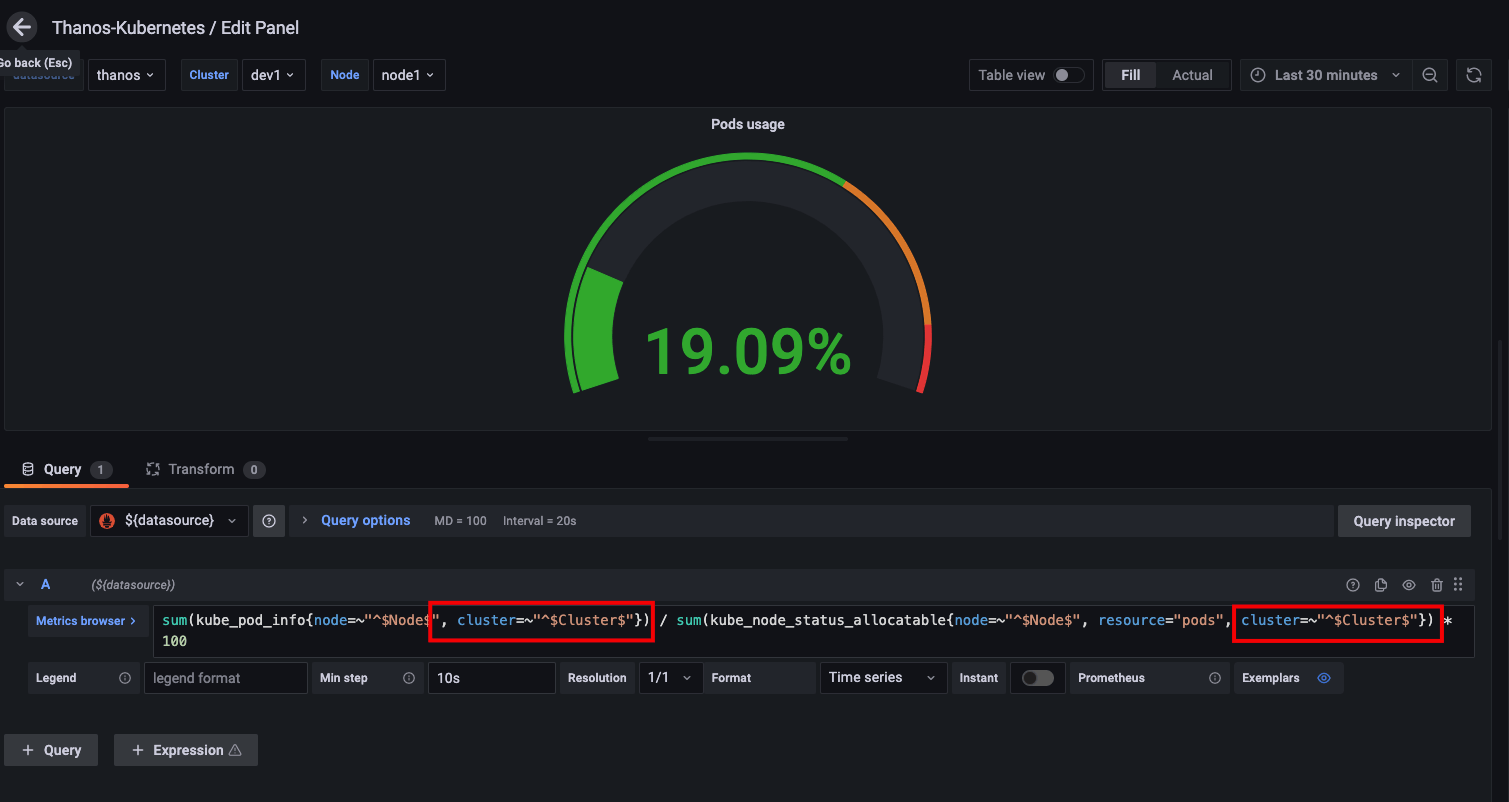
如上图,需要在每个视图的表达式中增加一个额外的过滤条件,cluster=~"^$Cluster$"}。当然,也可以将面板导出,在编辑器中批量修改之后再导入 Grafana。
6.3 查看 Thanos 和 Prometheus 数据源
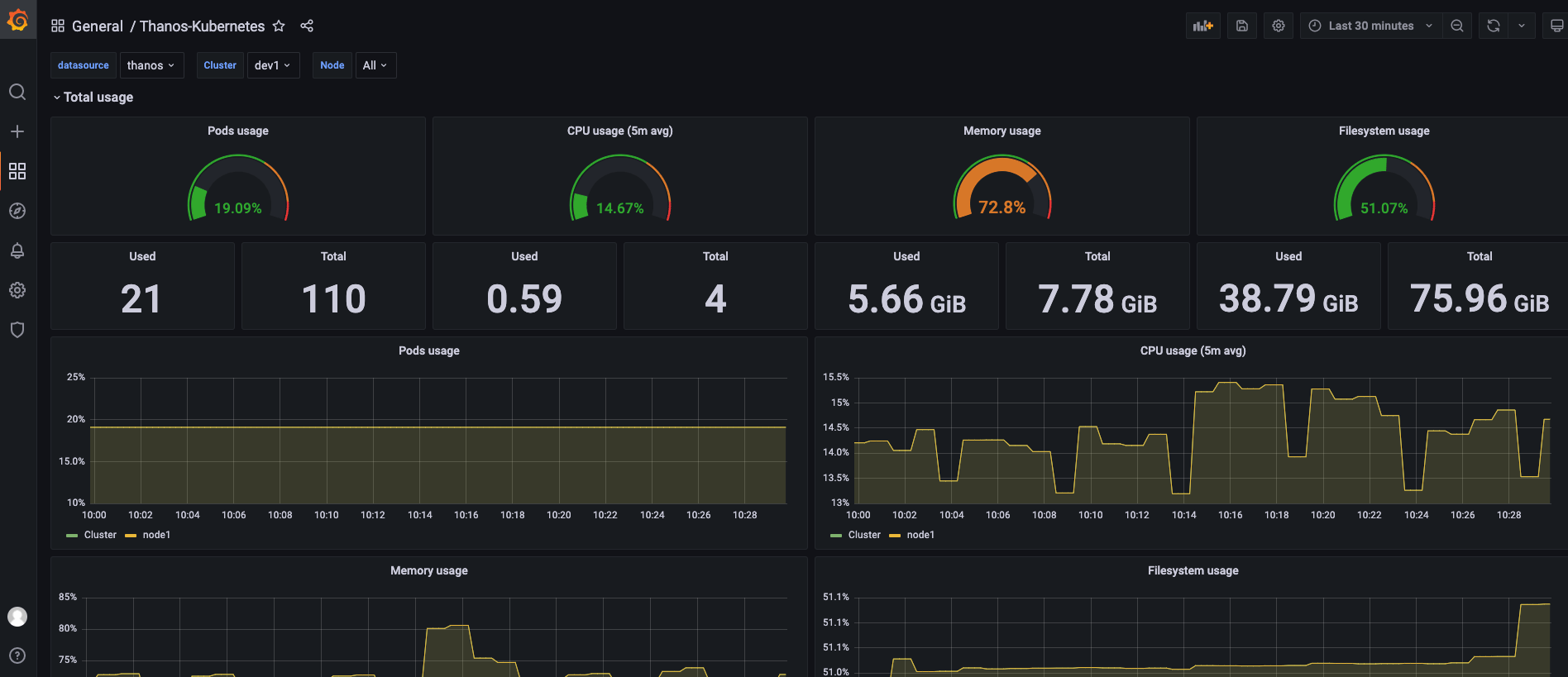
- 使用 Thanos 数据源
- 使用 Prometheus 数据源
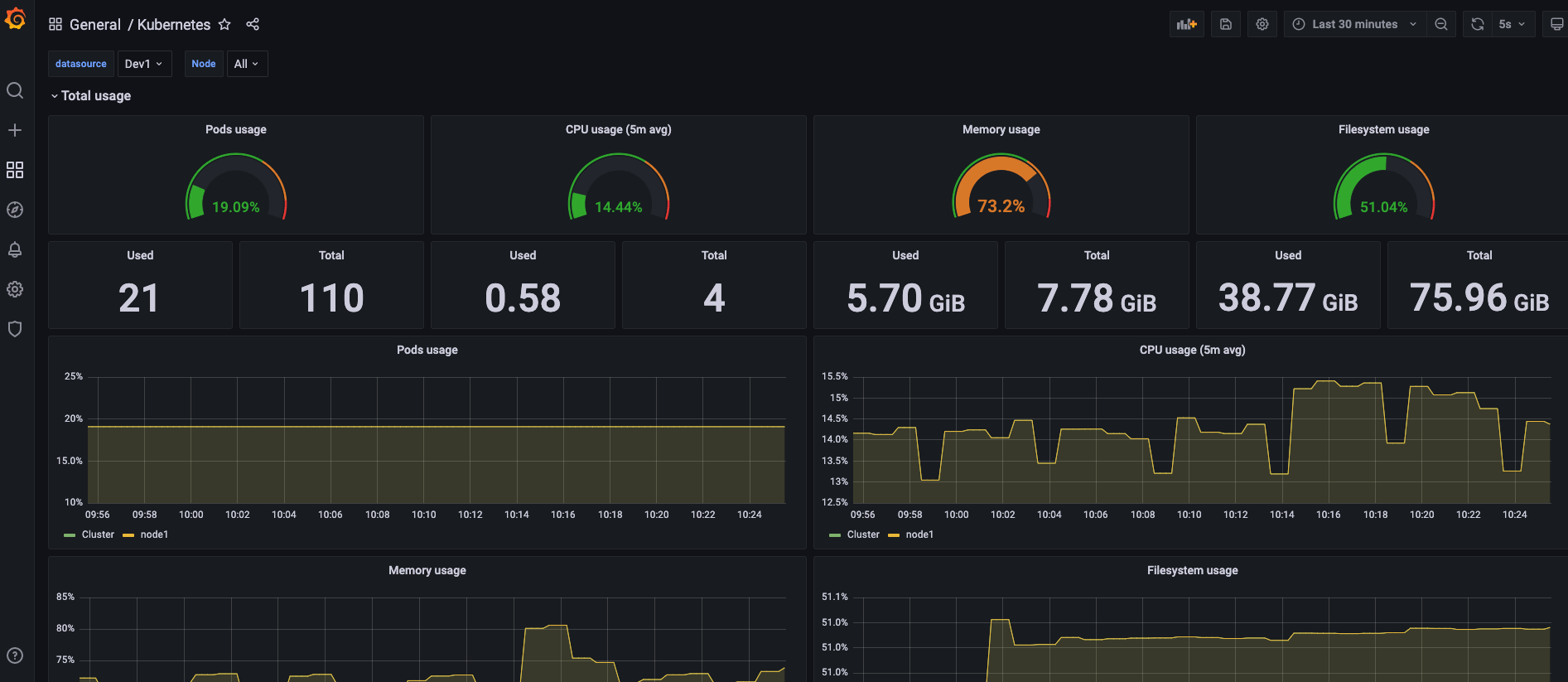
对比两个面板的数据,可以发现他们展示的指标一致。因此,我们可以使用一个 Thanos 数据源替代多个 Prometheus 数据源分散管理的场景。
这里数据的时间尺度没有达到 Thanos Compact 组件的参数设置,因此没有体现出降采样的效果。
7. 总结
本篇主要是阐述了监控数据层管理的一些想法。
首先是数据要分层,短期数据直接存储在就近的 Prometheus,长期数据存储在 Thanos 的对象存储中。短期数据提供给告警系统的高频查询,长期数据提供给人用于分析。
选择 Thanos 的主要原因是其降采样。Thanos compact 组件提供了 5 分钟、1 小时的降采样,以 Prometheus 每 15s 采样频率计算,压缩将达到 20 倍、240 倍,能够大大缓解长周期查询压力。采用 Sidecar 模式时,短期的数据会通过 Grpc 调用 Prometheus 的 API 查询。
最后当然是将本地用的 6 个集群都接入了 Thanos。只有亲自尝试过之后,才会真切地体会到其中的一些细节和处理逻辑。虽然架构图、文档、博客看了不少,但是都不如自己亲自尝试一次。
