1. Go 中的并发模型
1.1 通信模型 CSP
CSP 全称 Communicating Sequential Process ,通信顺序进程,描述的是一种并发通信模型。Process 可以使用很多个 Channel ,而 Channel 不关心谁在使用它,只负责收发数据。
Go 社区中,有一句非常著名的论断: 不要通过共享内存来通信,要通过通信来共享内存。意思是,不要在 Process 之间传递指针,而应该封装成对象,丢到 Channel 中,等待 Process 的消费。
CSP 中的 Process/Channel 对应 Go 语言中的 Goroutine/Channel ,是 Go 并发编程的基石。Goroutine 用于执行任务,Channel 用于 Goroutine 任务之间的通信。
1.2 两级线程模型
用户线程只是用户程序中的一堆数据,内核线程才是系统中的实际线程。用户线程得到调度时,内核线程读取用户线程数据进行执行。
因此,有必要了解一下用户线程和内核线程的关系,也就是线程模型。根据两者映射关系,可以分为一对一、多对一、多对多三种调度模型。(一个用户线程绑定到多个内核线程的模型,目前没有实际案例。)
一对一,一个用户线程绑定一个内核线程。借助于内核的调度,可以很方便地实现并发,但是内核线程频繁切换,调度成本很高。多对一,多个用户线程绑定一个内核线程。通过程序逻辑,控制多个线程的调度,但是只绑定了一个内核线程,只是宏观上的并发,不是真正的并行。多对多,多个用户线程绑定多个内核线程。这样可以充分利用多核的运算性能。
两级线程模型将用户调度和内核调度分开,用户调度只需要关注用户线程与逻辑处理器的调度,内核调度只需要关注逻辑处理器和物理处理器的调度。
1.3 调度模型 G-P-M
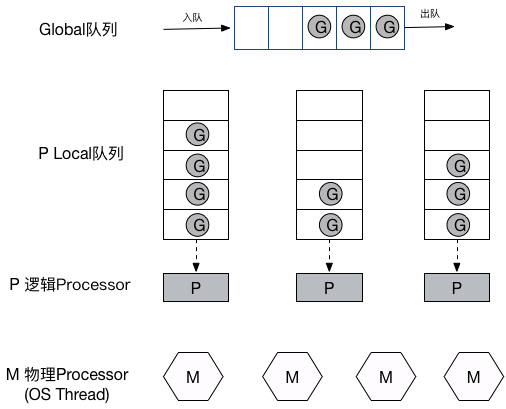
Go 能充分利用 CPU 多核性能,很重要的一点就是基于多对多线程模型,实现了 G-P-M 调度模型。有些语言的并发性能,依赖于第三方库,在第三方库中实现了用户线程、协程的调度。但在 Go 语言中,这种调度的能力直接作为语言特性被提供。下图是 Go 调度器的模型:
先来看下相关的概念:
- G ,Goroutine
每个 Goroutine 对应一个 G 结构体,用于存储 G 运行堆栈、状态,也就是一个执行逻辑。
- P,Processor
逻辑处理器,G 需要绑定到 P 才能被调度,P 向 M 提供内存分配状态、任务队列等上下文环境。
- M,Machine
物理处理器,P 需要绑定到 M 才能被调度。
调度的过程是这样的,G 创建后全部进入 Global 队列,等待调度。P 找到空闲的 M ,绑定之后,开始执行 Local 队列中的 G 。如果 G 进行系统调用,导致 M 处于阻塞状态,那么 P 将带着 Local 队列进行漂移到其他 M。当 P 的 Local 队列中没有 G 时,会依次从 Global 队列、其他 P 的 Local 队列中获取 G,直到全部 G 执行完成。
一个 Goruntine 初始内存只要 2KB ,因此只需要很少的资源就可以达到很高的并发量。但其占用的内存可以不断地增长,在 64 位机器上可达 1GB。这样,既保证了启动速度、数量,又兼顾了某些大内存消耗的场景。
2. 代码中的 Goroutine 和 Channel
Goroutine 是实际并发执行的实体。借助 Channel 通信,Go 实现了 Goroutine 之间传递的数据和同步。
2.1 Goroutine
Goroutine 是用协程实现的。什么是协程?协程是一个轻量级的线程,一个执行逻辑。但是这个执行逻辑不是由 OS 调度,在 Go 语言中由 Goroutine 的调度器来管理和调度这些协程。
G-P-M 模型就是 Goroutine 的调度器的实现模型。下面我们直接看个例子:
| |
通过 go 关键字,就可以很方便的将函数以非阻塞的形式并发执行。如果没有 time.Sleep ,主程序将不会等待打印 2/3 - goroutine ,而直接退出。
2.2 Channel 的生命周期
- 创建
Channel 需要使用 make 进行创建,Channel 的零值为 nil。
| |
- 写数据
| |
- 读数据
| |
- 关闭 Channel
| |
在读写数据时,有点类似 Linux 系统中的管道操作。
2.3 Channel 分类
根据数据流方向,可以将 Channel 分为三种:
- 声明 T 类型的双向通道
通常,使用的都是双向通道。
| |
- 声明只能发送 T 类型的通道
| |
- 声明只能接受 T 类型的通道
| |
根据是否带缓冲区域,Channel 又分为两种:
- 不带缓冲,可以看作是同步模式,默认采用这种模式
发送和接收同时发生,当有一方没有就绪时,另一方会处于等待状态。
| |
- 带缓冲,可以看作是异步模式
缓冲区未满时,发送和接收是异步的,当缓冲区满时,发送才会阻塞,等待有数据被消费。
| |
在使用完 Channel 之后,需要关闭 Channel 。如果继续发送数据,则会引发 Panic 。但可以继续读取 Channel 中的数据,没有缓冲区的 Channel 返回的是零值,有缓冲区的 Channel 接收完数据之后,也是零值。这保证了,即使 Channel 关闭,Channel 中的数据不会丢失,依然能够得到可靠的逻辑处理。
3. 通信示例
- Channel 通信
在 G-P-M 的示例中,通过 time.Sleep 等待 Goroutine 的完成。但是 Goroutine 的完成时间是不确定的,可能几十毫秒、也有可能几十秒,这种控制方式是不可靠的。
无缓存的 Channel 可以用于这类通信场景。下面是一个相关的示例:
| |
如果 Goroutine 不涉及数据的传输,这里也可以声明一个布尔类型的 Channel , done := make(chan bool) 。当 Goroutine 完成全部执行逻辑之后,往 done 中写入一个布尔类型即可。
- WaitGroup 控制 Goroutine
Go 的优势是高并发,意味着可能同时具有很多个 Goroutine 在执行。那么如果控制多个 Goroutine 的并发行为呢?答案就是 WaitGroup 。一起看下面的示例:
| |
这段代码每次执行的结果都不一样,因为并发的同等优先级的Goroutine 执行顺序无法控制。
WaitGroup 是通过计数器和信号量实现并发控制的。wg.Add 时,计数器 + 1 ;wg.Done() 时,计数器 -1 。
