1. 相关背景
早上 10:00 因同事需求,我通过工具在集群上创建 Kubernetes Job 执行任务。
工具创建 Job 时,会拿到集群上的全部节点,然后逐个绑定节点创建 Job。例如,如下集群:
| |
那么工具会创建 7 个 Job。由于有些集群中,master 节点是不允许调度的,在 Job 中容忍设置了 TaintEffectNoSchedule 容忍不可调度的节点。
这里的 node7、node8 节点实际上已经关机。
2. 事故时间线
按照预期,执行完工具的 Job 创建命令,应该就完事了。但是故事才刚刚开始:
- 10:31:02 告警系统提示,节点 CPU 5分钟负载过高
通过 top 命令,很快就发现是 kube-controller-manager 占用了太多 CPU。联想到 10:00 的变更,很快我就发现莫名创建了很多 Pod,怀疑是 Pod 太多导致 kube-controller-manager 压力过大。
- 10:39:00 开始清理 Pod
这一步才是噩梦的开始。从监控数据看,在事故前半个小时,机器的 CPU 负载是缓慢上升,当开始清理 Pod 时,机器完全失去了响应。
原因是,使用了 kubectl delete pod 清理 Pod。由于 kubectl 是通过 kube-apiserver 修改 etcd,然后 kube-controller-manager 异步完成删除任务。
但问题的关键在于,有近 3W Pod,而 master 节点只有 2C4G 的配置。瞬间删除 3W Pod 引发
kube-controller-manager、Etcd高负载直接让节点失去了响应。从监控图的 CPU 使用率看就是这样:
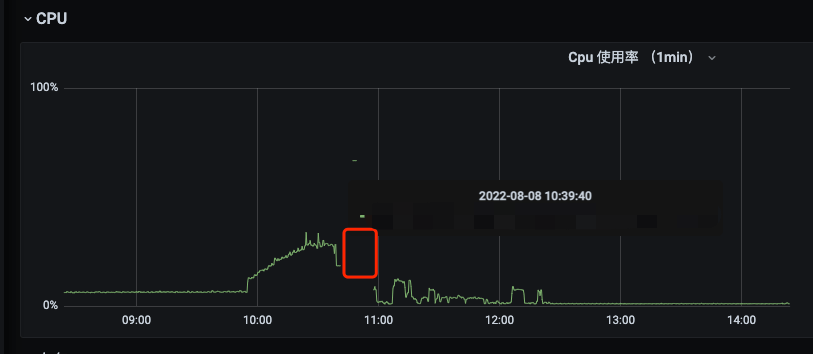
CPU 使用率表示的是对 CPU 的利用率,而 CPU 负载表征的是 CPU 的繁忙程度。比如,很多低计算密度的任务,就可能会导致 CPU 使用率低,CPU 负载很高。这里 CPU 使用率的监控数据直接就没了,说明 Prometheus 从主机的 exporter 已经拉取不到数据。
- 11:05:00 开始陆续扩容 master 节点
集群上有 3 台 master, kube-controller-manager 会进行选主,每台 master 上都部署了 etcd,因此全部 master 节点都需要升配置,直接拉到云厂允许的最高配置。
需要注意的是,不要三台同时升级,等一台就绪之后再升级另外一台,因为集群上还有很多负载。
- 11:18:00 升配完成,但依然报错
kube-controller-manager、Etcd 持续报错,但没有影响工作负载。
- 12:24:00 直接操作 etcd 清理 Pod 恢复集群
由于忽略了 Pod 的数量级,采用 kubectl 删除 Pod、Namespaces 一直不成功,kube-controller-manager、Etcd 持续报错。虽然 master 节点的配置已经升级至很高,但依然不能解决问题。在此,停留排查了很久,没有思路。最后想起来,完全失去响应是在开始删 Pod,才找到思路,直接删除 Etcd 数据。之前写的一篇文档里面有 Etcd 相关的一些操作配置: Etcd、Etcdctl 应用实践
执行一下命令,批量删除 xxx 命名空间下的 Pod 就解决了问题:
| |
3. 反省
- 清理环境
线上的运维操作要谨慎,不仅要保障结果的准确性,还要尽量消除变更之后的影响。
这里疏忽的点是,没有清理 Job。如果清理了 Job,可能就不会有问题。
- Kubernetes Job 需要设置 backoffLimit
实际上在 Kubernetes 1.16、master 代码分支上,都能看到默认的 backoffLimit 是 6,也就在会 Job 会重试 6 次,最多执行 7 次。工具在创建 Job 时,遗漏了这个参数:
| |
但在关机的节点上,默认的 backoffLimit 并未生效,而是以极快的速度不停创建 Pod,一个多小时两个 Job 重试共达到近 3W 次。
- 有待复现继续跟踪
场景不太好复现,Kubernetes 1.16、多 Master 节点、Worker 节点关机、Job 不设置 backoffLimit、Job 直接设置 nodeName,还在实验中,后续继续跟进。
