1. 关闭 affinity-assistant 之后
在前面的博文中,我通过关闭 affinity-assistant、使用 NFS 存储,平均每条流水线执行时间节约了近 30 秒。[1]
- affinity-assistant 的影响
在关闭之前,创建 Pod 的时序图如下:
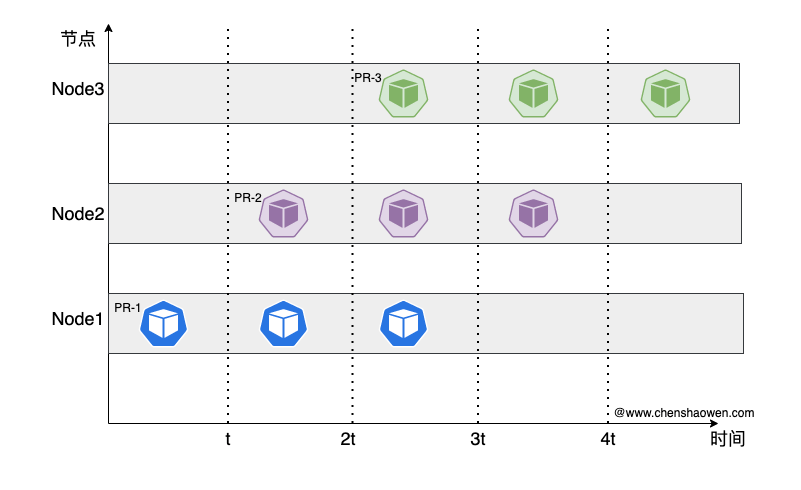
由于 affinity-assistant 开启,每条流水线绑定在一个节点执行。
在关闭之后,创建 Pod 的时序图如下:
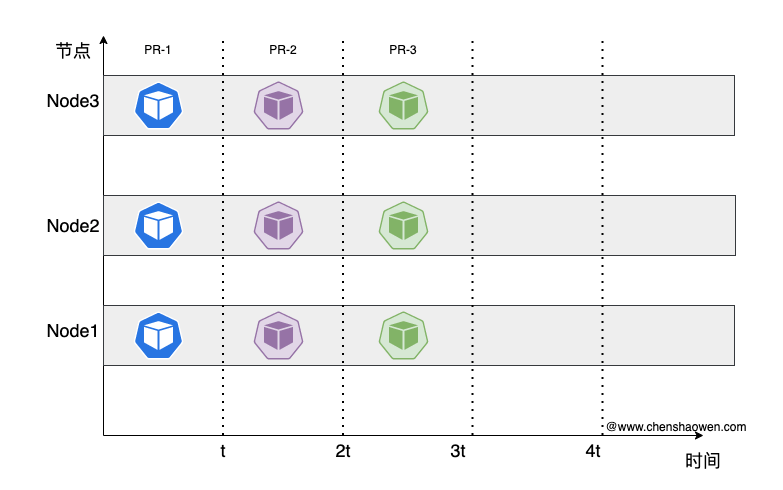
在多条流水线执行并发任务时,这种方式能有效节省 Pod 的创建时间。
- 使用 NFS 存储
PV 的使用分为 create、attach、mount 几个处理阶段,得益于 NFS 的古老,没有实现复杂的存储控制和附加功能,构建效率得到再次大大提升。
2. IO 一直跑不满
上线上面的优化之后,构建系统的性能得到很大改进,从用户的反馈可以看出,确实提升了不少。
ps,中间下线了一段时间,所以导致用户有种过山车的感觉
新的问题是,在构建高峰期时,平时需要 2-3 min 执行完成的流水线,随着并发的增多,需要 5-6 min。
- 查看监控
Grafana 图如下:
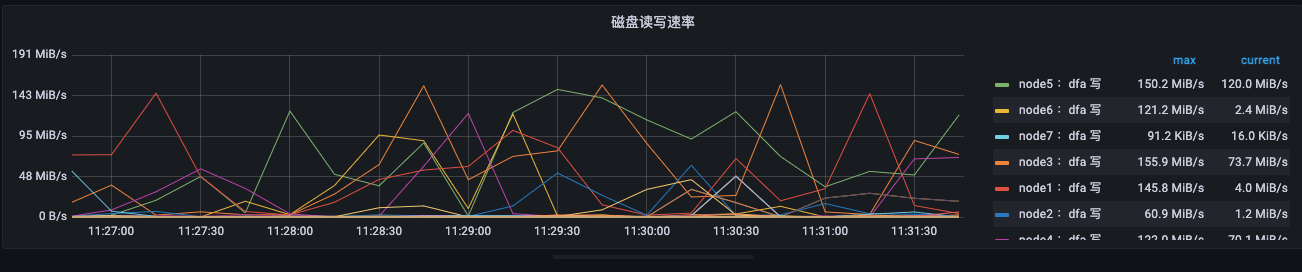
IO 速度并不大,150MB/s 以内。但我们使用的硬盘是企业级的 SSD,这与预期相差极大。联系技术售后,他表示符合预期,而且这还不是稳态,等磁盘写满之后,速度会更低。只有重新格式化,才能获得短暂的高速。
其他人一度怀疑是,Docker build 时没有充分利用系统资源。但是在前面的博文中,我逐一验证,进行了排除,最后的结论是 Docker build 默认没有限制资源的使用,只是 Overlay IO 会比磁盘慢。
- 初测磁盘速度
| |
IO 测出来 1.2 GB/s。但为啥,我们只能用到 150MB/s 以内。
关注构建系统的人也被误导,认为是软件问题,其实被忽略的是文件大小。做测评其实是一件非常不容易的事情,能够对系统进行有效评估,必须要求对系统的全部关键因子有着深刻理解。漏掉任何一个因素都可能得出完全相反的结论。
- 再测磁盘速度
在构建系统中,代码仓库、镜像文件都是以小文件为主,大量文件都只有几 KB 。如果测试时,选择一个块 1MB 肯定是不行的,得测试 4K 的随机读写。
安装 fio
| |
安装 opscli [2]
| |
开始测试
| |
看到测试结果 140MB/s,与监控速度基本吻合。
3. 无限 IO 能力
硬件受物理、资金、复杂的企业流程限制,无法提供高配,只能从软件架构侧优化。
下面是当前的存储现状,全部流水线共用一个 NFS Server。当 Pod 运行在某个节点时,节点会挂载 NFS Server 的文件目录。
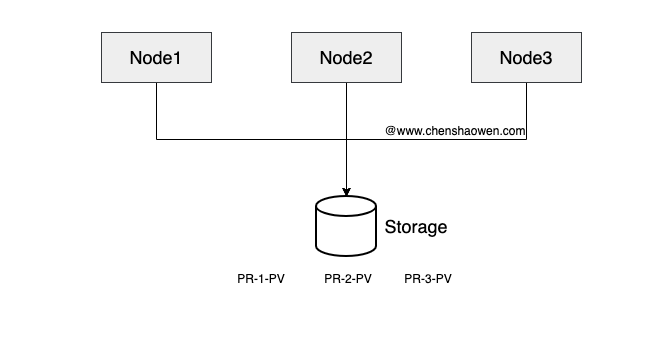
这种情况下 IO 很容易出现瓶颈。下面是一个新的存储方式,我们提供了一个存储池 NFS-1、NFS-2、NFS-3… NFS-10,部署了 10 个 NFS Server 对应 10 块不同的磁盘。在 Kubernetes 集群中,对应着 10 个 StorageClass。如下图:
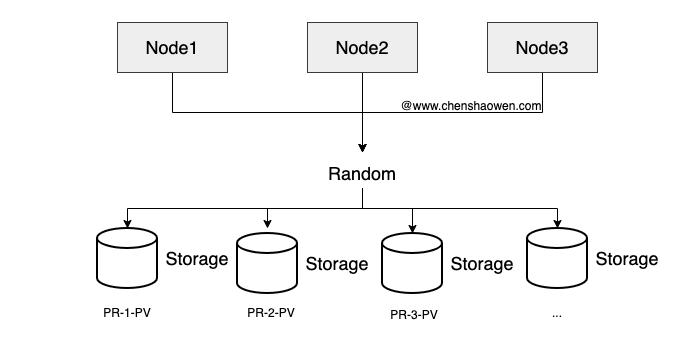
Tekton 下,我们通过提交 PipelineRun 执行流水线,而 volumeClaimTemplate 中是可以设置 storageClassName 的。格式如下:
| |
我们只需要将 storageClassName 值随机设置为 NFS-1、NFS-2、NFS-3…NFS-10 之一即可。当然,如果能获取到实时的 IO 指标,优先选择低负载的存储更好。
为什么说是无限的 IO 能力?因为只需要添加磁盘、部署 NFS、部署 nfs-client-provisioner、将 StorageClass 添加到可选存储列表中,即可为构建系统横向扩展 IO 能力,而对现有系统几乎没有影响。
4. 什么时候应该扩容
可以观察如下指标:
irate(node_disk_io_time_seconds_total{node=~"$node",device!~'^(md\\d+$|dm-)'}[3m])
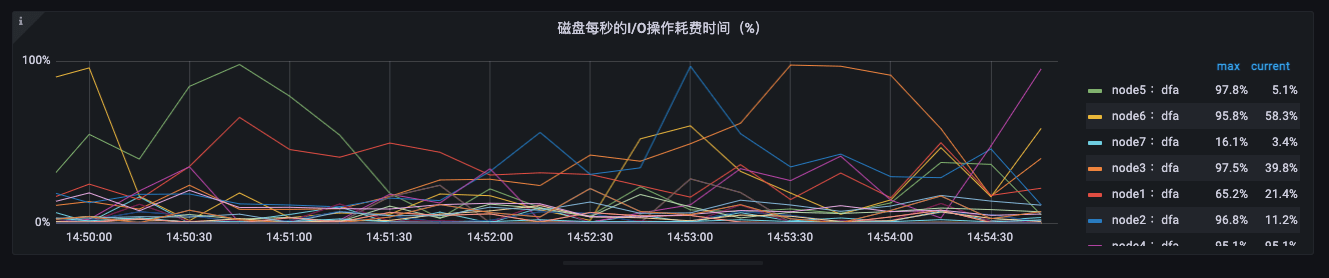
不能只盯着磁盘速度,需要重点关注磁盘 IO 的负载。
如果某个磁盘上面的指标持续接近 100%,那么说明该磁盘已经过载,需要减少构建任务。如果大量磁盘持续接近 100%,说明需要进行扩容了。
扩容有两种方式:
- 垂直扩容,换 IO 性能更好的磁盘
- 水平扩容,增加磁盘数量
垂直扩容比水平扩容操作简单,但成本高,可扩容的空间有限。通过加磁盘,扩展 IO 应该是更优的选择。
5. 总结
本篇主要是优化构建系统,以期获得无限 IO 扩展能力。构建是吃资源的大户,加 CPU、Mem,上 SSD 是常见的一些手段,但在实际生产环境 IO 依然具有明显瓶颈。本文主要给出如下观点:
- 测评是一件很专业的事,给结论务必谨慎
- Tekton 构建集群中,可以通过构建存储池,设置不同 StorageClass 扩展 IO 能力
- 磁盘速度只是一个维度,持续集成更应该关注磁盘 IO 的负载
