1. 业务背景
当企业达到一定规模时,完全依赖于公有云基础设施,IT 成本会很高。
采购物理机器的成本可以摊薄到未来 3~5 年,之后机器并不会报废,而是会继续超期服役。私有云需要配比一定运维人员、购买专线带宽、机房费用等,IT 服务达到一定规模才能有效降低成本。
因此,中大型企业才会采用混合云的方案,将一部分应用部署在公有云,一部分应用部署在私有云。这也促成了托管云服务的发展,云厂商提供纳管私有机器的服务,以便能够快速对接自家的公有云服务。
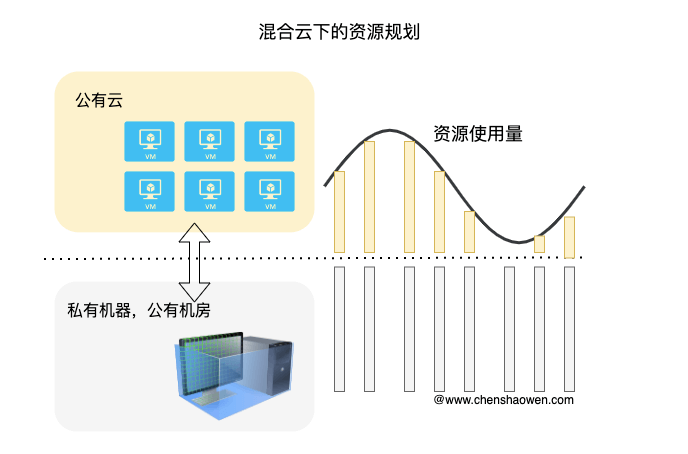
如上图,私有云的机器用来满足基本的业务资源需求,公有云的机器用来补充业务高峰期的资源需求。而 Kubernetes 作为基础设施,当然也需要适配混合云的场景。
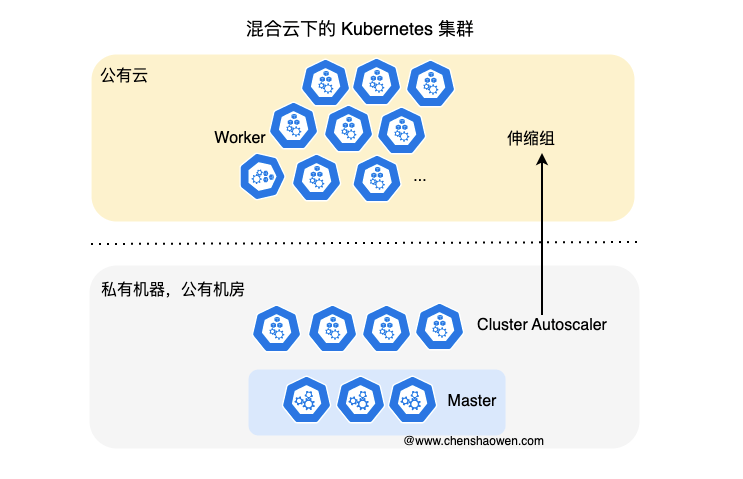
如上图,是一个混合云下的 Kubernetes 集群,私有机房(Master + 部分 Worker)+ 公有云(部分 Worker)。采用 Cluster Autoscaler 组件,对接公有云的弹性伸缩组服务,按需扩容或缩容 Worker 节点。
私有云的机器成本基本是固定的,而公有云的机器成本是按需计费的。在保障业务 SLA 的前提下,尽可能的减少公有云机器的使用,就是我最近在做的事情。
2. Request 为何如此重要
2.1 有利于调度均衡
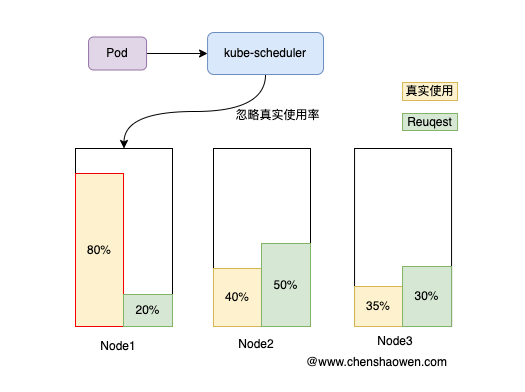
Request 是资源的请求量。如上图,当调度器在给 Pod 选择一个合适的 Node 时,Node 上 Pod 的 Request 总和越少,打分越高,越容易被选中。
如果给每个 Pod 都设置了很低的 Request,你会发现调度非常不均,有些节点负载很高,但调度器还是会选择这些节点。
因为默认的调度器是静态调度,只看 Request 和 Node 上的 Request 总量,而不考虑实际使量。
Request 保障当前应用分配有足够资源,是用来保护自己的;Limit 是用来限制当前应用,是用来保护其他应用的。
你可以不设置 Limit,但一定要设置 Request。
2.2 HPA 依赖于 Request 值扩缩容
HPA 计算资源使用率的公式是:
currentUtilization = int32((metricsTotal * 100) / requestsTotal)
当使用率超过阈值时,HPA 会增加 Pod 副本数量。而这里的 Total 意味着,HPA 计算的是全部 Pod 的资源消耗。
这里有两个问题需要思考
- 一个 Pod 可能有多个容器,一个容器使用率 90%,一个容器使用率 10%
在 Kubernetes v1.27 中有一个 Beta 特性 ContainerResource,可以指定容器作为计算对象,而忽略 Sidecar 等其他容器。
- 多个 Pod 的资源消耗不一样,一个 Pod 使用率 90%,一个 Pod 使用率 10%
从研发侧,在开发应用时,就应该考虑多副本的均衡性,避免出现单个副本任务过重的情况。如果是长链接导致的不均衡,应该有再平衡机制。同时,还应该支持优雅重启,避免某个 Pod 负载过高被 Kill 之后,影响服务的 SLO。
从运维侧,可以适当降低 Limit 值,通过 Kill Pod 的方式,让请求分散到其他 Pod 上。
3. 如何设置 Request 和 Limit
3.1 设置 Request
前面说到 Request 是用来保护当前应用的,应该能够满足应用的基本使用。但 Request 太高,又会导致资源浪费。
- CPU
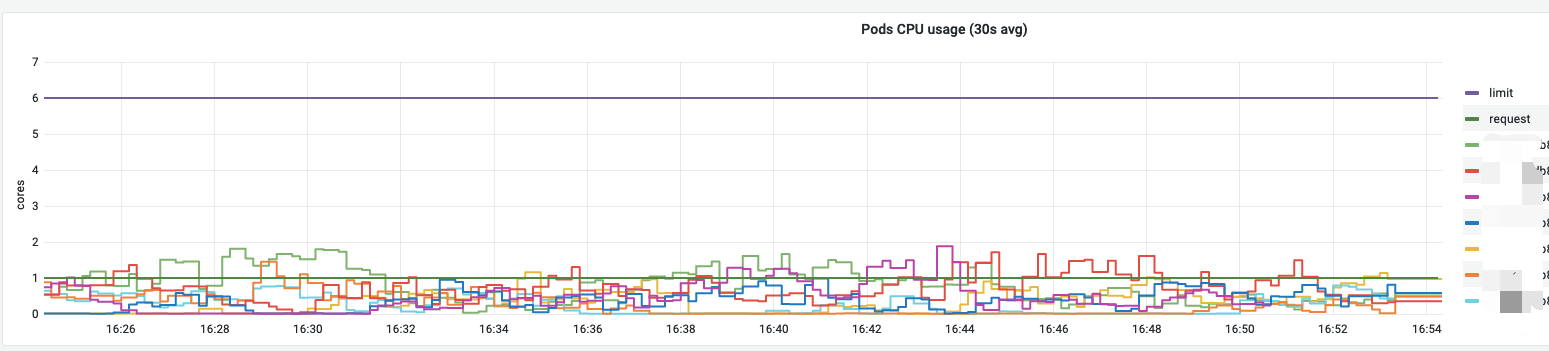
如上图,Request 应该满足大部分时间段下 CPU 使用。
clamp_min(max(quantile_over_time(0.6, irate(container_cpu_usage_seconds_total{cluster="$cluster", namespace="$namespace", deployment="$deployment"}[2m])[1w:2m])), 0.5)
quantile_over_time 函数统计 60 百分位的使用需求,clamp_min 函数设置最小值为 0.5。
- Memory

clamp_min(max(quantile_over_time(0.8, max(sum (container_memory_working_set_bytes{cluster="$cluster",image!="",name=~"^k8s_.*", namespace=~"$namespace", deployment=~"$deployment"}) by (pod)))[1w:2m]), 500 * 1024 * 1024)
内存是不可压缩资源,需要设置一个较高的 Request,以保障应用的正常运行。因此,设置的百分位比 CPU 要高。
3.2 设置 Limit
设置 Limit 是为了保护其他应用,避免当前应用的资源消耗过高时,影响其他应用的正常运行。
- CPU
如下图,应用经常会碰到,CPU 使用率很低,但是 CPU 限流很严重,需要不断地提高 CPU Limit,而过高的 Limit 又会导致节点不稳定。同时,有些计费系统,是以 Limit 为基础进行计费的,过高的 Limit 会增加业务成本。
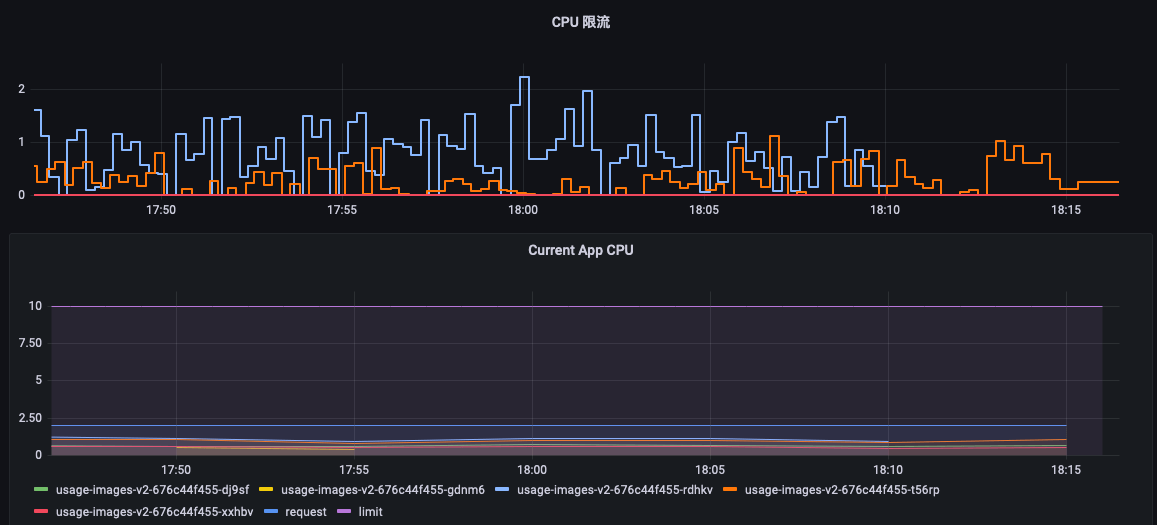
这种情况是因为,Prometheus 的采样频率是 15s,监控粒度太粗,采集不到实时的 CPU 使用情况。而如果采集 1s、100ms 监控数据时,很有可能是这样的。
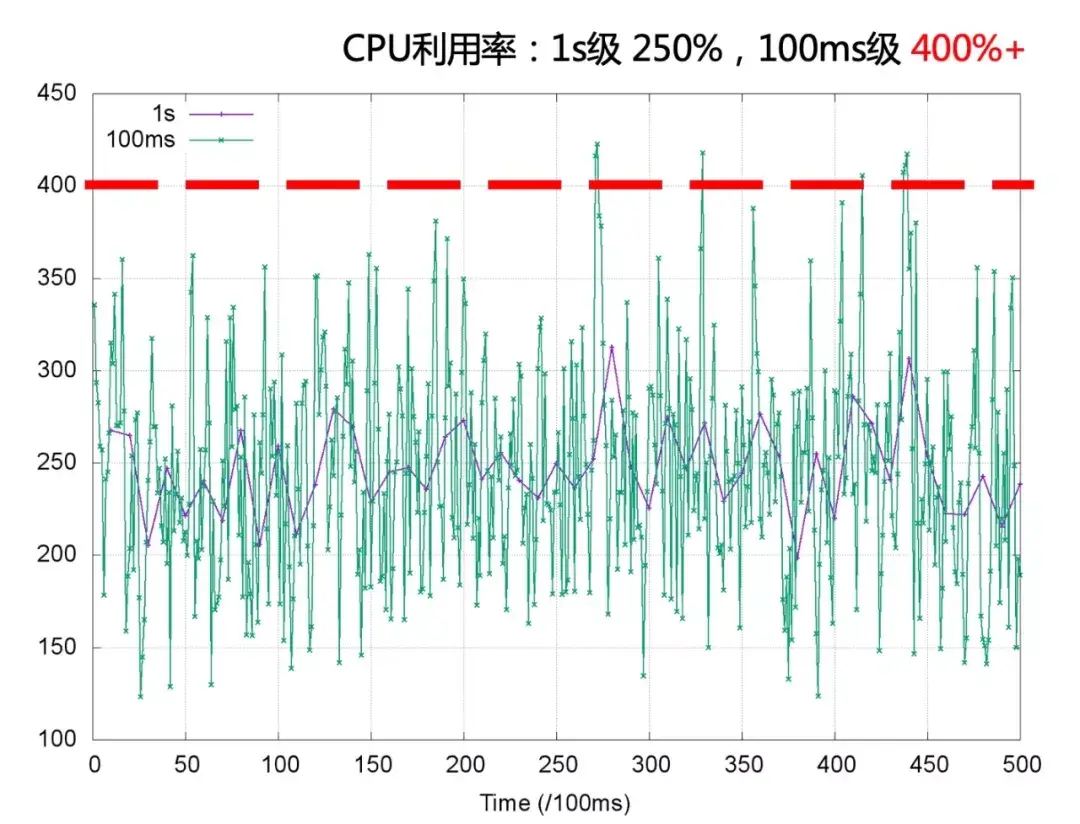
使用率已经超过 400%。
在这种情况下,首先得升级内核版本至 5.14 及以上。5.14 内核新增的 CPU Burst 策略,通过累计算法,可以应对这种瞬时的 CPU 需求。
clamp_min(max(quantile_over_time(0.99, irate(container_cpu_usage_seconds_total{cluster="$cluster", namespace="$namespace", deployment="$deployment"}[2m])[1w:2m])) + quantile_over_time(0.99, (sum(irate(container_cpu_cfs_throttled_seconds_total{cluster="$cluster", name=~"^k8s_.*", namespace=~"$namespace", deployment=~"$deployment"}[10s])))[1w]), 0.52)
Limit = 99 百分位 CPU 使用核数 + 99 百分位 CPU 限流核数,同时不小于 0.52 核。
如果不升级内核,99 百分位 CPU 限流核数会很高,需要适当调整。
- Memory
内存超了会被内核 OOM,你会发现内存的监控值始终不会超过 Limit。因此 Limit 应该超过 Request,但又不会触发 OOM 为宜。
quantile_over_time(0.995, container_memory_working_set_bytes{cluster="$cluster", namespace="$namespace", deployment="$deployment"}[1w:5m])
可以以 99.5 百分位的内存作为 Limit 起始值,逐步增加,直到不再触发 OOM。
4. 调试前的准备工作
了解了业务背景、相关的要点,在正式配置之前还需要进行一些预防措施,避免事故。
4.1 业务 SLO 告警
紧盯业务的关键 SLI 是能够大胆调试的关键,如果不能保障 SLA 一切的优化都是徒劳。
这里选取的是成功率、堆积量 A\B 作为核心指标。
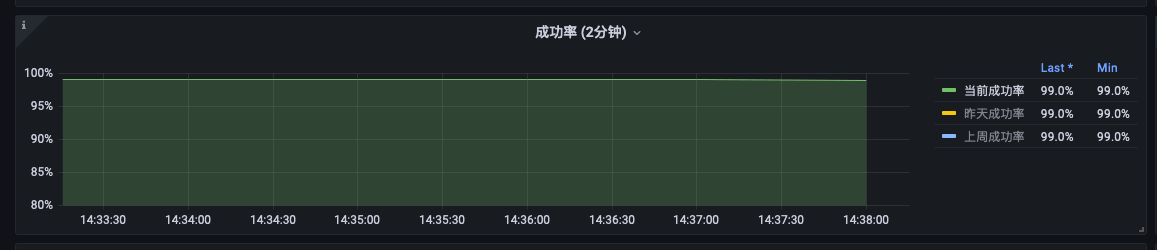
成功率 > 99%
这一成功率要求,也影响了很多参数百分位的设置。

堆积量 A < 1000

堆积量 B < 1000
建议以最能体现使用方体验的指标作为 SLI,而不是以研发、运维的视角来定义 SLI。
4.2 集群应用 Pod 相关告警
由于调试 HPA 会涉及 Pod 的创建,为了避免扩容失败,需要对 Pod 的相关指标进行监控。
- Pod 未就绪
sum by (cluster, app, pod)(kube_pod_status_ready{condition='false',exported_namespace='default'})
- Pod 等待调度
sum by (cluster, app, pod)(kube_pod_status_phase{phase='Pending',exported_namespace='default'})
- Pod OOM
sum by (namespace,pod) ((kube_pod_container_status_restarts_total{exported_namespace="default"} - kube_pod_container_status_restarts_total{exported_namespace="default"} offset 10m >= 1) and ignoring (reason) min_over_time(kube_pod_container_status_last_terminated_reason{exported_namespace="default",reason='OOMKilled'}[10m]) == 1)
- Pod 限流
sum (rate (container_cpu_cfs_throttled_seconds_total{namespace="default",name=~"^k8s_.*"}[5m])) by (pod)
4.2 应用分级
线上的应用面对潮汐流量,在资源使用上总会有波动。一旦这种波动超过了节点的承载能力,就会导致节点驱逐应用,影响业务的稳定性。
而 Kubernetes 驱逐的策略是根据 QoS 类型来决定的,QoS 类型分为三种:
- BestEffort:没有设置 Request 或 Limit,当节点资源不足时,优先驱逐
- Burstable:Request 和 Limit 不相等,当节点资源不足时,可以驱逐
- Guaranteed:Request 和 Limit 相等时,当节点资源不足时,尽量不驱逐
只用区分两种类型就可以,重点业务应用 Request、Limit 相等,非重点业务应用 Request、Limit 不相等。
4.3 开启 Pod 调度的亲和性
对于副本较多,普通应用可以开启软亲和性,尽量避免在同一个机器上调度。
| |
对于副本较少,重点应用可以开启硬亲和性,强制分散到不同机器上。
| |
对于副本较多的应用,最好使用软亲和性,避免 Cluster Autoscaler 不断扩容增加额外的成本。
5. 开始配置 HPA
5.1 新建 HPA 对象
如果有一个 Deployment 部署的应用 example,只需要创建一个 HPA 对象,指定 Deployment 的名称即可。
应用以下 yaml 对象
| |
或者执行命令
| |
创建 HPA 对象,它的目标是 example Deployment,最大副本数 5,最小副本数 2,目标 CPU 使用率 60%。当 Pod 平均 CPU 使用率超过 60% 时,HPA 会增加副本数量。
5.2 HPA 参数
由于我主要使用的是 HPA v1 cpu 指标,这里只介绍 v1 的几个主要参数。
- 副本数量下限
生产环境最少需要 2 个 Pod,避免单点故障。重点应用,最少需要 3 个 Pod。
- 副本数量上限
Pod 的数量会随着负载的上升,不断增加,按需使用,因此上限应该尽量大一些。如果平时副本 2-3 个,就给上限为 5。如果平时副本数量为 10-20 个,就给上限为 30。
上限最好设置得比平时多一些,同时设置为 5 的倍数为宜,方便识别扩容数量达到 HPA 上限之后,继续增加。
- CPU 使用率
CPU 使用率设置得越低,扩容时就越灵敏;设置得越高,资源的利用率就越低。通常可以根据应用的负载情况,设置为 50%-70%。
设置的策略是,先设置为 50%,等稳定之后,再逐步增加 5%。
6. 总结
本篇主要是记录了在给 60 个应用设置 HPA 的之后,遇到的问题和一些思考。主要内容如下:
- Request 在集群调度、HPA 中发挥了很重要的作用
- 通过 PromeQL 设置应用的 Request 和 Limit
- 调试 HPA 之前应该配置一些告警,保障服务的 SLA
- 配置 HPA 及相关参数
给不同应用设置 Request、Limit、HPA 副本上限、HAP 副本下限、HPA CPU 使用率,是一件繁琐的事情,建议先绘制一个 Grafana 计算面板,可以实时计算调试。类似下图:
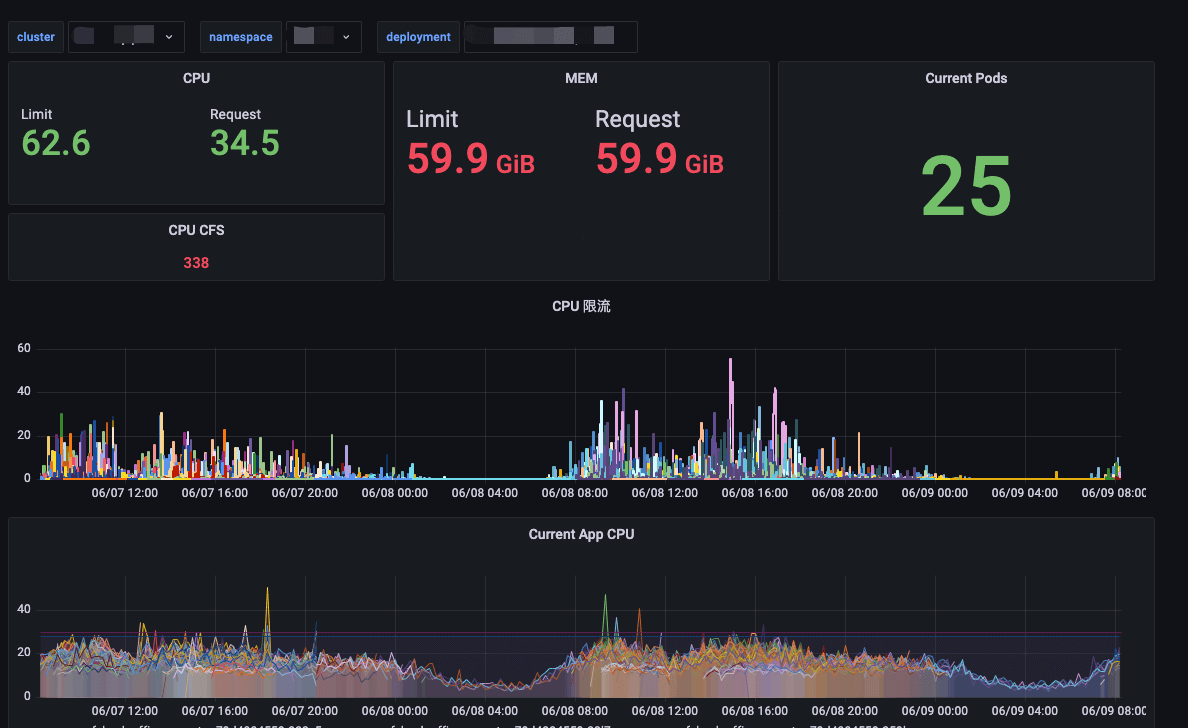
最终效果如下:
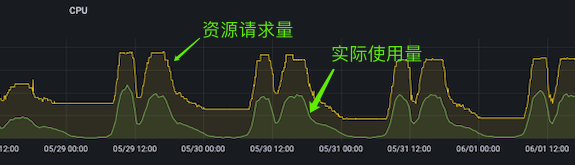
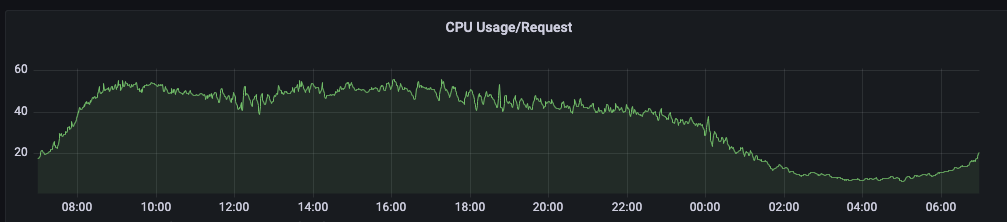
资源的请求量会随着使用量波动,而请求量又直接影响到公有云的机器使用数量。如下图是线上 Usage/ Request 的情况,也是我不断优化 HPA 相关参数的指引指标。
从云厂控制台的账单来看,HPA 相较于没有弹性,成本降低了 50%;在之前的实践中,CronHPA 相较于没有弹性,成本降低了 30%。
另外可以考虑的是,将长期占用的弹性公有云机器转移到私有云,或者采用公有云包年的结算方式,因为云厂的按需付费弹性主机价格比较高。
