1. 需求背景
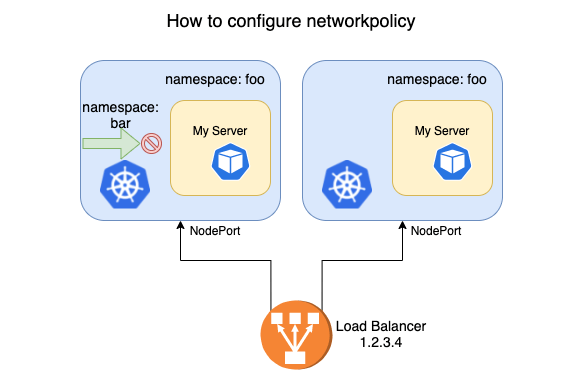
如上图,业务方需要隔离 namespae 的服务,禁止 bar 空间的负载访问,而允许用户从 Load Balancer (LB) 通过 NodePort 访问服务。可以很容易地写出一个网络策略:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: foo
spec:
podSelector:
matchLabels: {}
policyTypes:
- Ingress
ingress:
- from:
- ipBlock:
cidr: 10.2.3.4/32
- namespaceSelector:
matchExpressions:
- key: region
operator: NotIn
values:
- bar
|
然而从 LB 访问的流量被完全禁止,不符合预期。在技术社区检索得到的答案可能是,Kubernetes NetworkPolicy 主要针对的是集群内的访问策略,而外部流量经过 SNAT 之后,IP 发生变化无法命中策略。
不同的网络插件,使用不同的模式,配置会有差异。本文仅提供一个思路,以常见的 Calico IPIP 模式为例配置 NodePort 的流量访问策略。
2. 预备知识点
2.1 Kubernetes 中的 NetworkPolicy
在文档 Kubernetes 之网络隔离(内附十多种使用场景) 中,我对 Kubernetes 的 NetworkPolicy 有所描述,给出了很多示例。
NetworkPolicy 是 Kubernetes 中的网络隔离对象,用来描述网络隔离策略,具体实现依赖于网络插件。目前,Calico、Cilium、Weave Net 等网络插件都支持网络隔离功能。
2.2 Calico 的几种工作模式
在 BGP 模式下,集群中的 BGP 客户端两两互联,同步路由信息。
在 BGP 模式下,客户端连接数量达到 N * (N - 1),N 表示节点的数量。这种方式限制了节点的规模,社区建议不超过 100 个节点。
Route Reflector 模式下,BGP 客户端不需要两两同步路由信息,而是将路由信息同步到若干指定的 Route Reflector 。全部 BGP 客户端只需要和 Route Reflector 建立连接即可,连接数量与节点数量线性相关。
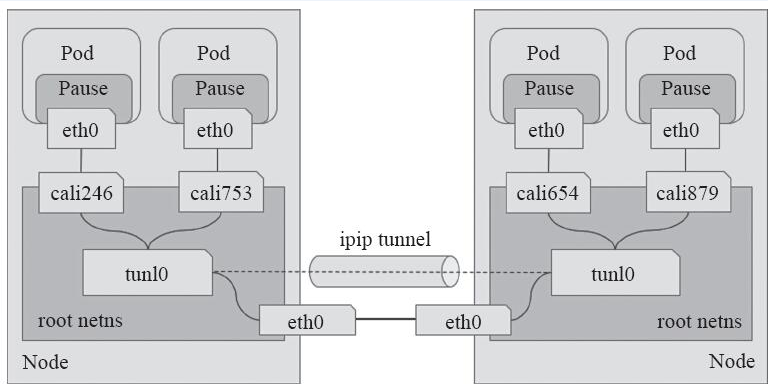
不同于 BGP 模式,IPIP 模式是通过 tunl0 在节点之间建立隧道,实现网络连通。下图描述了 IPIP 模式下 Pod 之间的流量。
3. 为什么网络策略不生效
在前面的文档 Kubernetes 中如何获取客户端真实 IP 中,我描述过 externalTrafficPolicy 对服务流量的影响。
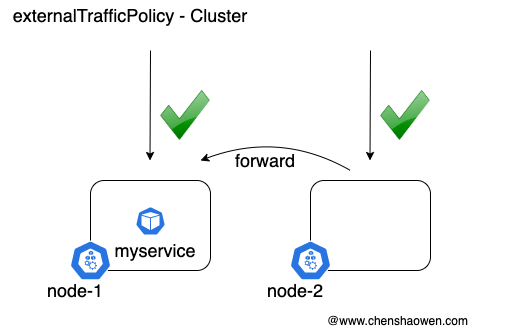
Cluster 模式下,如果访问 node-2:nodeport,流量将被转发到有服务 Pod 的节点 node-1 上。
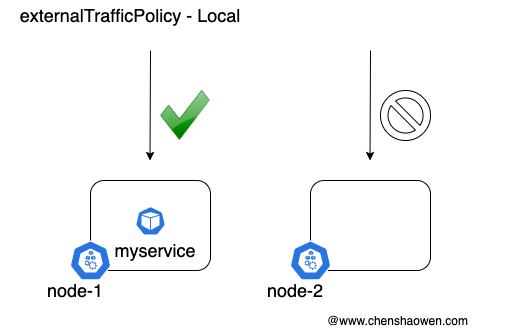
Local 模式下,如果访问的 node-2:nodeport,流量不会被转发,无法响应请求。
通常我们默认采用的是 Cluster 模式,而 Cluster 模式在转发流量时会进行 SNAT,也就是修改源地址。这会导致访问请求无法命中网络策略,误以为网络策略没有生效。
这里尝试两种解决办法:
- 将 SNAT 之后的源地址也添加到访问白名单中
- 使用 Local 模式。由于 LB 有探活的功能,能将流量转发到具有服务 Pod 的节点上,从而保留了源地址。
4. NodePort 下的 NetworkPolicy 配置
4.1 测试环境
v1.19.8
IPVS
1
2
3
4
5
6
| kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
node1 Ready master,worker 34d v1.19.8 10.102.123.117 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://20.10.6
node2 Ready worker 34d v1.19.8 10.102.123.104 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://20.10.6
node3 Ready worker 34d v1.19.8 10.102.123.143 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://20.10.6
|
1
2
3
4
| kubectl -n tekton-pipelines get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tekton-dashboard-75c65d785b-xbgk6 1/1 Running 0 14h 10.233.96.32 node2 <none> <none>
|
负载运行在 node2 节点上
1
2
3
4
| kubectl -n tekton-pipelines get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
tekton-dashboard NodePort 10.233.5.155 <none> 9097:31602/TCP 10m
|
4.2 NodePort 流量如何转发到 Pod
这里主要考虑两种情况。
- 访问不存在 Pod 负载的节点 node1
ipvsadm -L
TCP node1:31602 rr
-> 10.233.96.32:9097 Masq 1 0 0
TCP node1:31602 rr
-> 10.233.96.32:9097 Masq 1 0 0
TCP node1.cluster.local:31602 rr
-> 10.233.96.32:9097 Masq 1 0 0
TCP node1:31602 rr
-> 10.233.96.32:9097 Masq 1 0 0
TCP localhost:31602 rr
-> 10.233.96.32:9097 Masq 1 0 0
可以看到访问 node1:31602 的流量被转发到了 10.233.96.32:9097,也就是服务 Pod 的 IP 地址和端口。
接着看路由转发规则,10.233.96.0/24 网段的访问都会被转到 tunl0,经过隧道到达 node2 再转到服务中。
1
2
3
4
5
6
| route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.233.92.0 node3.cluster.l 255.255.255.0 UG 0 0 0 tunl0
10.233.96.0 node2.cluster.l 255.255.255.0 UG 0 0 0 tunl0
|
- 访问存在 Pod 负载的节点 node2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| ipvsadm -L
TCP node2:31602 rr
-> 10.233.96.32:9097 Masq 1 0 0
TCP node2:31602 rr
-> 10.233.96.32:9097 Masq 1 0 0
TCP node2.cluster.local:31602 rr
-> 10.233.96.32:9097 Masq 1 0 1
TCP node2:31602 rr
-> 10.233.96.32:9097 Masq 1 0 0
TCP localhost:31602 rr
-> 10.233.96.32:9097 Masq 1 0 0
|
与 node1 一样,访问 node2 上的 NodePort 服务也会被转发到服务 Pod 的 IP 地址和端口上。
但是路由规则不一样,目的地址为 10.233.96.32 的包会发给 cali73daeaf4b12 。而 cali73daeaf4b12 与 Pod 中的网卡构成一组 veth pair,流量会被直接发往服务 Pod 中。
1
2
3
4
5
6
7
| route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.233.90.0 node1.cluster.l 255.255.255.0 UG 0 0 0 tunl0
10.233.92.0 node3.cluster.l 255.255.255.0 UG 0 0 0 tunl0
10.233.96.32 0.0.0.0 255.255.255.255 UH 0 0 0 cali73daeaf4b12
|
从上面命令返回可以知道,如果访问不存在 Pod 负载的节点,流量会经过 tunl0 转发;如果访问存在 Pod 负载的节点,流量不经过 tunl0 直接被路由到 Pod 中。
4.3 方案一,将 tunl0 添加到网络策略白名单
node1
1
2
3
4
| ifconfig
tunl0: flags=193<UP,RUNNING,NOARP> mtu 1440
inet 10.233.90.0 netmask 255.255.255.255
|
node2
1
2
3
4
| ifconfig
tunl0: flags=193<UP,RUNNING,NOARP> mtu 1440
inet 10.233.96.0 netmask 255.255.255.255
|
node3
1
2
3
4
| ifconfig
tunl0: flags=193<UP,RUNNING,NOARP> mtu 1440
inet 10.233.92.0 netmask 255.255.255.255
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: foo
spec:
podSelector:
matchLabels: {}
policyTypes:
- Ingress
ingress:
- from:
- ipBlock:
cidr: 10.2.3.4/32
- ipBlock:
cidr: 10.233.90.0/32
- ipBlock:
cidr: 10.233.96.0/32
- ipBlock:
cidr: 10.233.92.0/32
- namespaceSelector:
matchExpressions:
- key: region
operator: NotIn
values:
- bar
|
不符合预期。全部经过 tunl0 的流量都会被允许。bar 命名空间的负载可以通过访问 node1:31602、node3:31602、tekton-dashboard.tekton-pipelines.svc:9097(非 node2 上的负载) 访问服务,无法对流量进行限制。
4.4 方案二,使用 Local 模式
- 修改 svc 的 externalTrafficPolicy 为 Local 模式
1
2
3
4
5
6
7
8
9
10
11
| kubectl -n tekton-pipelines get svc tekton-dashboard -o yaml
apiVersion: v1
kind: Service
metadata:
name: tekton-dashboard
namespace: tekton-pipelines
spec:
clusterIP: 10.233.5.155
externalTrafficPolicy: Local
...
|
1
2
3
4
5
6
7
8
9
| kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: test-network-policy-deny-all
namespace: foo
spec:
podSelector:
matchLabels: {}
ingress: []
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: foo
spec:
podSelector:
matchLabels: {}
policyTypes:
- Ingress
ingress:
- from:
- ipBlock:
cidr: 10.2.3.4/32
|
符合预期。使用上面的网络策略,可以满足业务需求,屏蔽 bar 命名空间的访问,允许外部通过 LB 转发到 NodePort 的访问。
5. 总结
网络是 Kuberntes 中相对难以掌握的部分,但网络又是对业务影响范围比较大、影响程度比较深远的一个方面。因此,多花一点时间在网络上,是必要而值得的。
本文主要结合业务需求,对 Calico 的网络模式进行了更进一步的阐述,解决了因为 SNAT 导致源 IP 发生变化,最终 NetworkPolicy 不符合预期的问题。
在 Calico 的 IPIP 模式下,针对 NodePort 的访问策略需要使用 externalTrafficPolicy: Local 流量转发模式。再结合网络策略最佳实践,先禁用全部流量之后,添加白名单策略。
6. 参考
