简单介绍一下项目需求: 项目组需要对外发布文档,文档撰写使用的是Markdown,对外需要使用HTML。起初,使用的是Nginx+Jekyll的解决方案。随着文档的增加,文档系统对搜索功能有了强烈的需求。笔者在另外一篇文章中有所讨论,但是这几种方案,有的搜索效果不理想,有的需要依赖其他服务,显得有些重。于是,便有了本文的实施方案。
1. 工具介绍
- Whoosh是一个纯Python实现的全文搜索组件。Whoosh不但功能完善,而且速度很快。
- Haystack是一个第三方的Django app,提供全文检索功能。可以对Model里面的内容进行索引、搜索。同时,Django-haystack支持Whoosh、Solr、Xapian、Elasticsearc四种全文检索引擎后端,实质上是一种全文检索的框架,使用时可以自由选择搭配。
- Jieba是一个Python中文分词组件,其包含多种功能,本文使用了其中的ChineseAnalyzer中文分词功能。
2. 设计方案
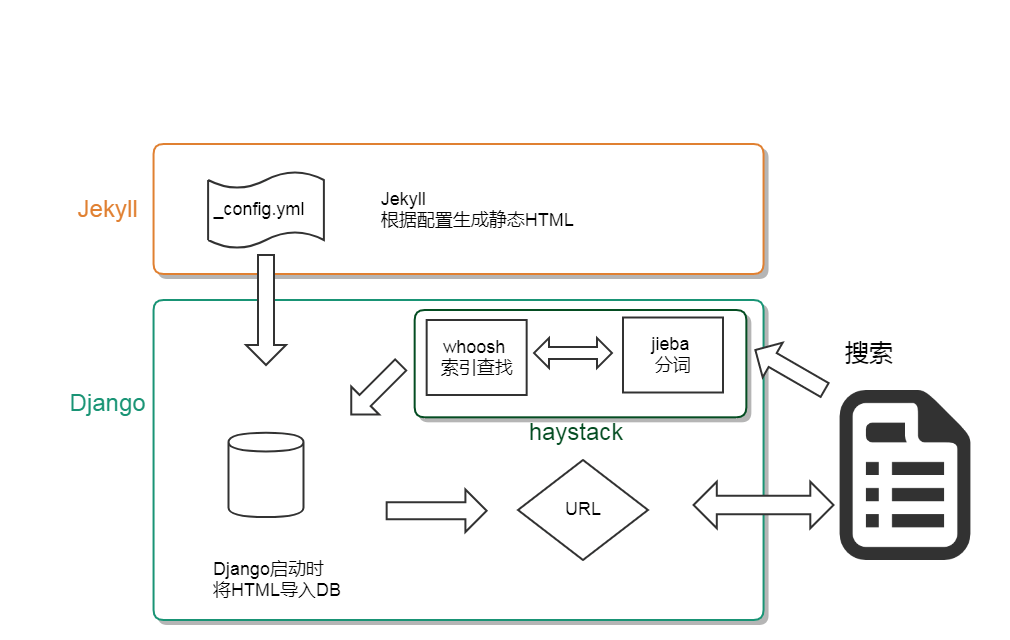
方案思路
- 1.将Jekyll作为Markdown转HTML的工具,最终得到本地所见即所得的HTML文档
- 2.使用Python爬虫工具BeautifulSoup,将静态的HTML解析后导入DB
- 3.通过Jieba分词,利用Whoosh建立查询索引
- 4.直接通过Django匹配.html的URL,从数据库中获取数据,对外提供文档服务,可以确保Nginx+Jekyll方案的链接依然有效。
3. 实施方案
3.1 创建文档 app
在项目目录,创建一个 Django app,命名:document。文档系统为两级目录结构,第一级为分类,第二级为文档。
例如:
- doc/type1/aaa.html
- doc/type2/bbb.html
document/models.py
1
2
3
4
5
6
7
8
9
10
11
12
13
| from django.db import models
class Document(models.Model):
'''
@summary: jekyll生成的文档
'''
file_name = models.CharField(u'文件名', max_length=255)
uri = models.CharField(u'URI', max_length=255)
tag = models.CharField(u'标签', max_length=255)
title = models.CharField(u'标题', max_length=255)
doc_html_text = models.TextField(u'文档(txt格式)')
doc_html = models.TextField(u'文档(HTML格式)')
doc_html_all = models.TextField(u'整个文档(HTML格式)')
created_time = models.DateTimeField(u'创建时间', auto_now_add=True)
|
3.2 读取HTML
这里利用BeautifulSoup对HTML文件中的内容,进行了简单的筛选。是为了剔除导航部分的文本内容,增加搜索匹配的准确度。文档内容被markdown-body类包裹,标题被bk-title-style detail-title-right类包裹。
document/utils.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| # -*- coding: utf-8 -*-
import os
import copy
from bs4 import BeautifulSoup
from .models import Document
PROJECT_ROOT = os.path.dirname(os.path.abspath(__file__))
PROJECT_DIR, PROJECT_MODULE_NAME = os.path.split(PROJECT_ROOT)
def import_html_to_db(path=[], tag=''):
root_path = os.path.join(PROJECT_DIR, *path)
for root, dirs, files in os.walk(root_path, True):
for file in files:
if file.find('.') and file.split('.')[-1] == 'html':
_root = copy.deepcopy(root)
_uri = _root.replace(root_path, '')
if _uri.startswith(os.path.sep):
_uri = _uri[1:]
with open(os.path.join(PROJECT_ROOT, root, file)) as _f:
_doc_html = _f.read()
doc_html_obj = BeautifulSoup(_doc_html)
if doc_html_obj.find_all('div', class_='markdown-body'):
Document.objects.create(
file_name=file,
uri=_uri,
tag=tag,
title=doc_html_obj.find_all('h3', class_='bk-title-style detail-title-right')[0].text,
doc_html=doc_html_obj.find_all('div', class_='markdown-body')[0],
doc_html_text=doc_html_obj.find_all('div', class_='markdown-body')[0].text.replace('\n', ' '),
doc_html_all=_doc_html
)
|
3.3 安装配置haystack
1
2
3
| pip install django-haystack
pip install whoosh
pip install jieba
|
document/search_indexes.py,文件名一定要为search_indexes.py
1
2
3
4
5
6
7
8
9
10
11
12
13
| # -*- coding: utf-8 -*-
from haystack import indexes
from .models import Document
class DocumentIndex(indexes.SearchIndex, indexes.Indexable):
text = indexes.CharField(document=True, use_template=True)
doc_html = indexes.CharField(model_attr='doc_html')
def get_model(self):
return Document
def index_queryset(self, using=None):
return self.get_model().objects.all()
|
拷贝haystack/backends/whoosh_backend.py,重命名为document/whoosh_cn_backend。将分词器改为jieba,默认的分词器对中文支持不友好。
仅需要将原来的import StemmingAnalyzer,替换为jieba的ChineseAnalyzer即可。
1
2
| # from whoosh.analysis import StemmingAnalyzer
from jieba.analyse import ChineseAnalyzer as StemmingAnalyzer
|
1
2
3
4
5
6
7
8
9
| INSTALLED_APPS_CUSTOM = (
'haystack'
)
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'document.whoosh_cn_backend.WhooshEngine',
'PATH': os.path.join(os.path.dirname(__file__), 'whoosh_index'),
},
}
|
1
| python manage.py rebuild_index
|
执行命令后,settings.py同目录下,生成文件夹whoosh_index,包含索引信息。
settings.py中配置
1
| HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
|
4. Django中使用
4.1 使用haystack默认路由
1
| url(r'^search/', include('haystack.urls')),
|
template/search/search.html,模板文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| <form method="get" action="">
<table>
{{ form.as_table }}
<tr>
<td></td>
<td>
<input type="submit" value="Search" />
</td>
</tr>
</table>
<h3>结果</h3>
{% for result in page.object_list %}
<a href="/document/{{result.uri}}/{{result.file_name}"
>{{ result.object.title }}</a
><br />
{% empty %}
<p>没有搜索到结果.</p>
{% endfor %}
</form>
|
template/search/indexes/document/document_text.txt,查询字段配置
注意这里的子目录indexes,文件夹名是约定的,必须按照这样的格式。第一个document为Django app名,第二个document为Model表名,后缀_text。文本中,配置建立索引的字段。
1
| {{ object.doc_html_text }} {{ object.title }}
|
4.2 自定义View API
haystack也提供了,查询函数用于获取匹配的Model对象。
1
2
3
4
5
6
7
8
9
10
11
12
| from django.shortcuts import render
from haystack.forms import ModelSearchForm
from haystack.query import SearchQuerySet
def search(request):
page_size = int(request.GET.get('page_size', '10'))
page_num = int(request.GET.get('page', '1'))
form = ModelSearchForm(request.GET, searchqueryset=None, load_all=True)
searchqueryset = form.search()
results = [r.pk for r in searchqueryset]
docs = Document.objects.filter(tag=request.TAG, pk__in=results)[(page_num - 1) * page_size: page_num * page_size]
return render(request, 'search/search.html', {'docs': docs,'total': len(docs)})
|
