由于数据量剧增,系统响应很慢。对应用系统进行了一系列的优化工作,系统响应时间得到了数量级级别的优化效果。总体看,在压缩文件、加快网络访问方面的优化,对前端性能有显著提升效果。在存储过程、缓存、逻辑代码方面的优化,对后端性能提升有显著效果。本文整理了优化思路和方法。
1. 梳理链路
在优化之前,梳理整个链路尤为重要。
优化是一个系统工程,不能经过简单地增减就取得很好的效果。同时,并不是我们故意将系统设计得慢,而是设计系统的前提条件发生了变化,需要审视整个系统。优化就是要找出这些变化,并让系统适应这种变化。
下图,是对整个系统链路的梳理:一个接入层,一个逻辑层,一个存储层。
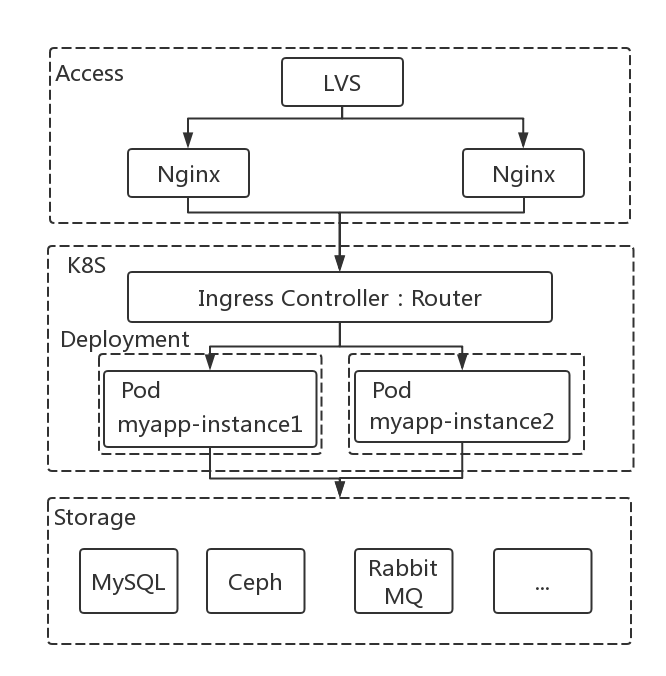
2. 项目背景和优化思路
这是一个商城 + 社区论坛的 Web 应用,还有小程序端。不仅要支撑商品的发布、更新、交易、日常运营,还需要支撑用户社区问答、关注点赞等社交功能。由于某些历史原因,系统的数据表多达 142 张。
一句话描述,就是大而杂。同时,开发人员只有一个前端,一个后端。
项目采用前后端分离的模式进行开发,优化时,也是顺着这个思路。前后端分别,先借助一定的分析工具,找到链路上耗时的节点,再进行优化。
下面是一些已经采取或即将采取的优化措施。
3. 前端
3.1 根据 PageSpeed Insights 分析优化
PageSpeed Insights 是由 Google 开发的网站分析和优化工具。有网页版,也有 Google Chrome 插件版 。
安装插件版之后,通过 F12 打开开发者工具,点击 【ANALYZE】。将会看到 PageSpeed 对页面的打分和修改意见。
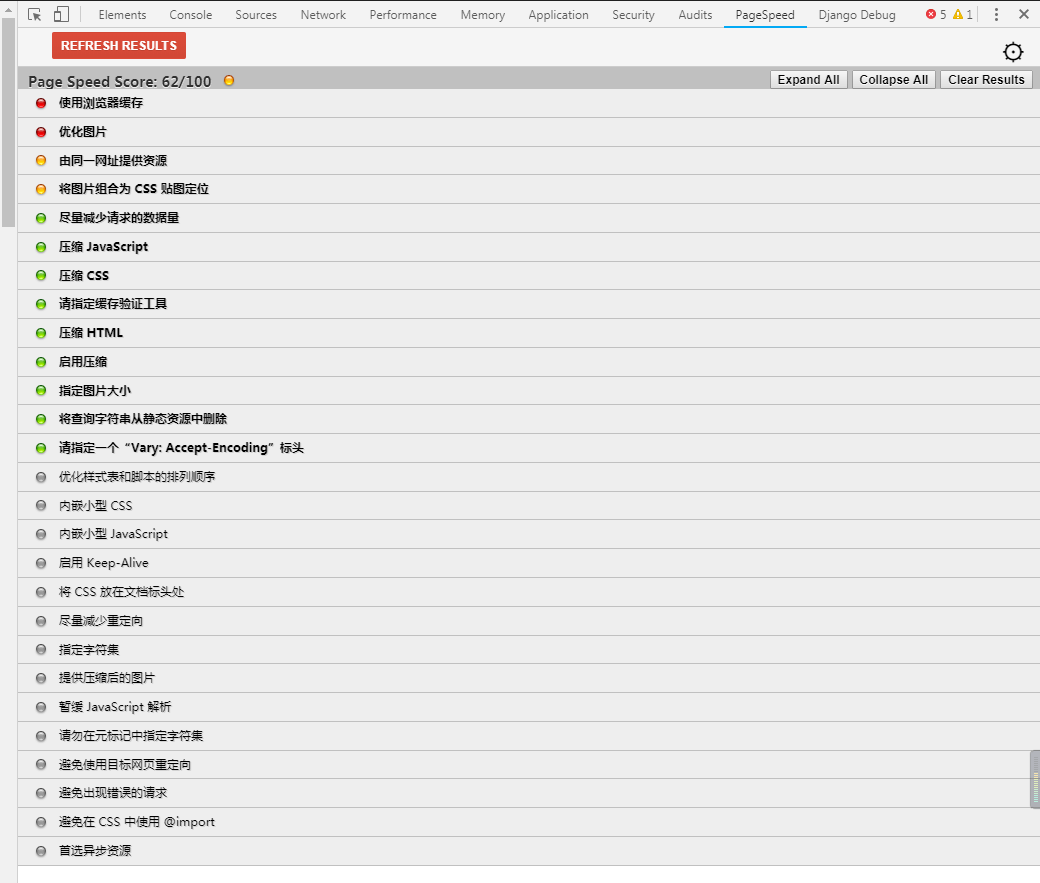
点击每一项意见,会显示更详细的内容。PageSpeed Insight 的分析包含以下几个方面:
- 优化缓存——让你应用的数据和逻辑完全避免使用网络
- 减少回应时间——减少一连串请求-响应周期的数量
- 减小请求大小——减少上传大小
- 减小有效负荷大小——减小响应、下载和缓存页面的大小
- 优化浏览器渲染——改善浏览器的页面布局
3.2 CDN 托管静态文件
CDN 技术主要优势:
访问速度更快
用户连接的是距离最近的 CDN 服务器,来获得内容,在访问速度上会得到显著提升。可用性
在用户流量过高、间歇性高峰和潜在服务器故障等高压力情况下,CDN 依然能保障用户能获取到内容。安全性
CDN 服务能够有效缓解各种攻击行为。
将前端静态文件托管到 CDN ,是对前端优化很重要的一个环节。当然,这种改造需要部署系统支持。
3.3 根据页面拆分前端静态文件
拆分前端打包的静态文件,是为了用户访问应用时,按需加载。而不必在首次加载页面时,请求全部文件。前端使用的是 webpack 3.6.0,在 webpackConfig 的 plugins 属性中新增如下内容即可:
| |
3.4 减少不必要的接口调用
由于前端开发人员不稳定,交接频繁,实现逻辑上存在不一致。同时,前端代码质量参差不齐,代码实现上不易于扩展和维护。主要存在以下情况:
- 在公共模块中已经调用的接口,路由子页面中重复调用
- 只属于某一个路由子页面的接口,每个页面都在调用
- 页面中同一接口,调用多次
这部分主要需要前端开发 Review 代码,在代码逻辑层进行优化。
4. 后端
本节分为两个部分,前面介绍几种性能分析工具,在分析数据的基础上,后半节主要介绍如何进行优化。
4.1 django-debug-toolbar 分析时间消耗
django-debug-toolbar 是一个不错的 Django 性能检测工具。django-debug-toolbar 主要提供以下几个方面的性能检测:
- 执行了多少条 SQL 语句
- 有多少时间花费在数据库上
- 执行了什么特殊的查询操作,每次查询花费多长时间
- 这些查询是有什么代码生成的
- 渲染页面都用到了哪些模板
- 冷/热缓存是如果影响性能的
- 安装
| |
- 配置
| |
url.py
| |
配置成功之后,就可以看到相关性能的检查数据:
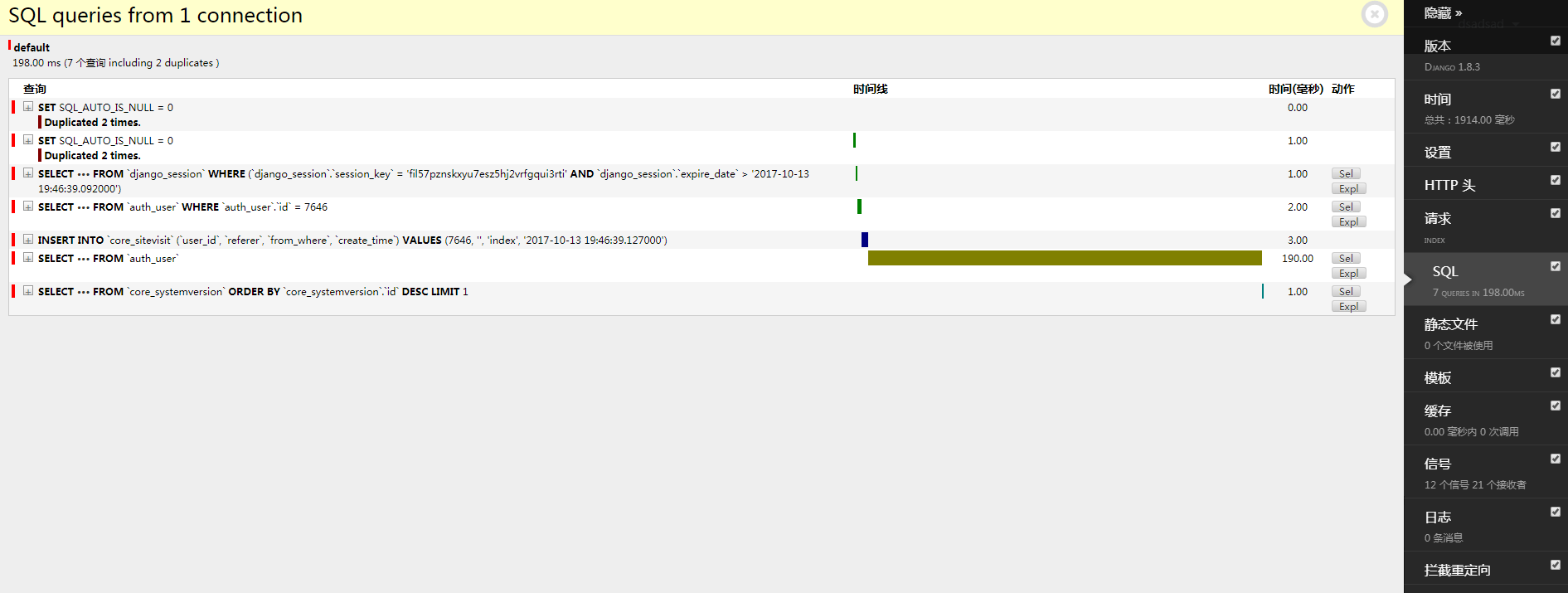
4.2 django-debug-panel 分析 Ajax
django-debug-panel 在 django-debug-toolbar 的基础上,提供了更好地对单页面应用和 Ajax 请求的支持。
- 安装
| |
- 配置
settings.py
| |
使用 panel 的中间件,替换 toolbar 的中间件。
middlewares.py
| |
安装 Chrome 扩展:Django Debug Panel
配置成功之后,就可以看到相关性能的检查数据:
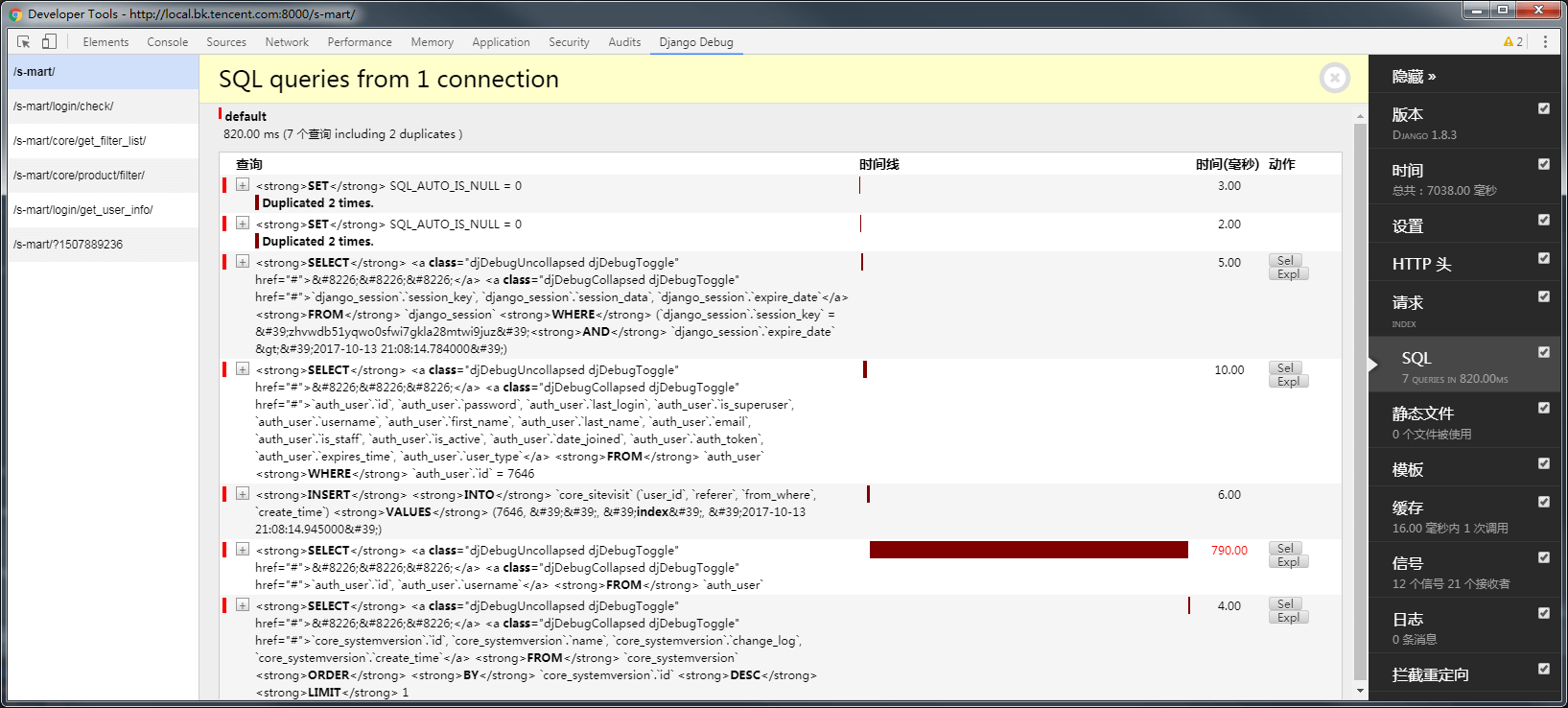
4.3 django-debug-toolbar-requests 分析 requests 请求
通常,我们会使用 requests 库,请求一些第三方的接口。这些第三方接口的性能也需要被关注。django-debug-toolbar-requests 在 django-debug-toolbar 的基础上,提供了对 requests 请求的支持。
- 安装
| |
- 配置
| |
在 DEBUG_TOOLBAR_PANELS 中添加 RequestsDebugPanel
| |
配置成功之后,就可以看到相关性能的检查数据:
4.4 Django 数据库优化
- 给搜索频率高的字段加索引
在 Django 中定义 Model 时,可以通过 db_index=True 给字段添加索引:
| |
给关键的字段添加索引,性能会得到很大提升,特别是数据量大、查询操作多时。可以参考这篇文档
但是索引并不是越多越好,索引可以极大的提高数据的查询速度,但是会降低插入、删除、更新表的速度。把握合适的度很重要。
- 合理利用 QuerySets 缓存
Django 的 QuerySets 有缓存,一旦取出来,会在内存呆上一段时间。看下面的这个例子:
| |
| |
all、count、exists 等函数调用才需要连接数据库,但是属性访问不需要连接数据库。如果是自定义的属性,需要使用 cached_property,添加缓存策略,可以参考这篇文档。
- 利用 iterator() 获取对象,避免 QuerySets 内存消耗
| |
QuerySet 会在缓存其结果,以便在重复计算时不会导致额外的查询。而 iterator() 将直接读取结果,不在 QuerySet 级别执行任何缓存。对于返回大量只需要访问一次的对象的 QuerySet,这可以带来更好的性能,显著减少内存使用。
- 尽量批量操作
批量操作能有效减少数据库连接的次数。
批量插入数据
| |
批量更新数据
| |
批量删除数据
| |
多对多关系
| |
4.5 合理利用缓存
缓存是优化性能的利器。缓存的思路是利用空间交换时间,避免重复计算。
在 Django 中常用的缓存方式有:
- 开发调试缓存
- 内存缓存
- 文件缓存
- 数据库缓存
- Memcache缓存(使用python-memcached模块)
- Memcache缓存(使用pylibmc模块)
根据不同粒度,又可以将缓存划分得更细:
- 整站缓存
只需要添加中间件即可:
| |
- 视图层缓存
| |
- 模板片段缓存
| |
- 定制缓存
Django 提供的 django.core.cache.caches 允许用户,自行设置、维护缓存。
| |
- 线程中的缓存
除了 Django 内置的缓存机制,利用 Python 的动态特性,在线程级别还可以进行更细粒度的缓存:
| |
将数据缓存在当前线程 local 中,这种优化方式对在一个请求内多次访问相同缓存的场景有比较好的效果。
实际上这是在使用内存缓存。
4.4 代码逻辑优化
- 正则表达式记得编译
| |
排序尽量使用 .sort()
- O(nlogn)
- 使用 key 比 cmp 效率更高
使用列表迭代表达式
| |
使用列表推导比上面快了 36%
| |
- 减少函数调用,尽量访问局部变量
| |
减少函数调用之后比上面快了 40%
| |
- 使用 set 判断元素是否存在
| |
使用 set 之后比上面快了 70000%
| |
