1. 使用 Query 聚合数据
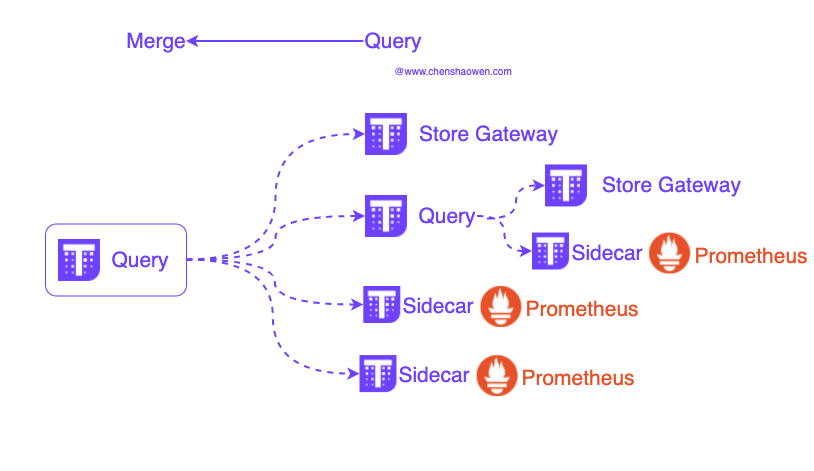
如上图,Thanos Query 可以对接的组件有:
- Thanos Store Gateway
- Thanos Query
- Thanos Receive
- Prometheus,借助于 Sidecar
利用 Thanos Query 之间的级联,我们可以实现跨组件的关联查询,组建超大型的监控系统。这也意味着,每个对接的组件应该提供足够快的 Prometheus API。整个接口的响应时间依赖于最慢组件的响应时间。
当然你也可以在不同层级,提供不同级别的查询数据源。如下图:
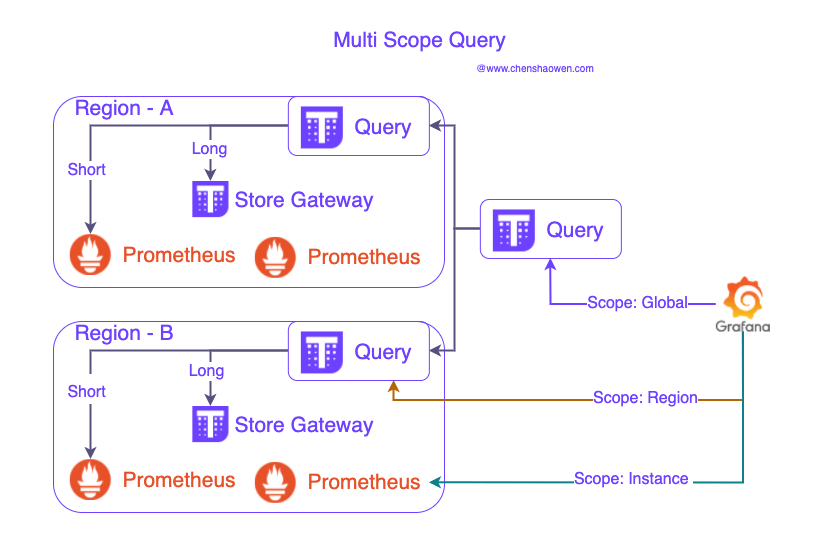
在全局、区域、实例级别都可以提供查询接口。
2. 指标数据的拆分及生命周期管理
Thanos 采用的是存储空间换计算时间和内存的方式,加速长周期指标的查询。Thanos Compact 组件会将小的存储块,合并为大的存储块。如下图,Compact 组件还提供了对存储块的管理能力:
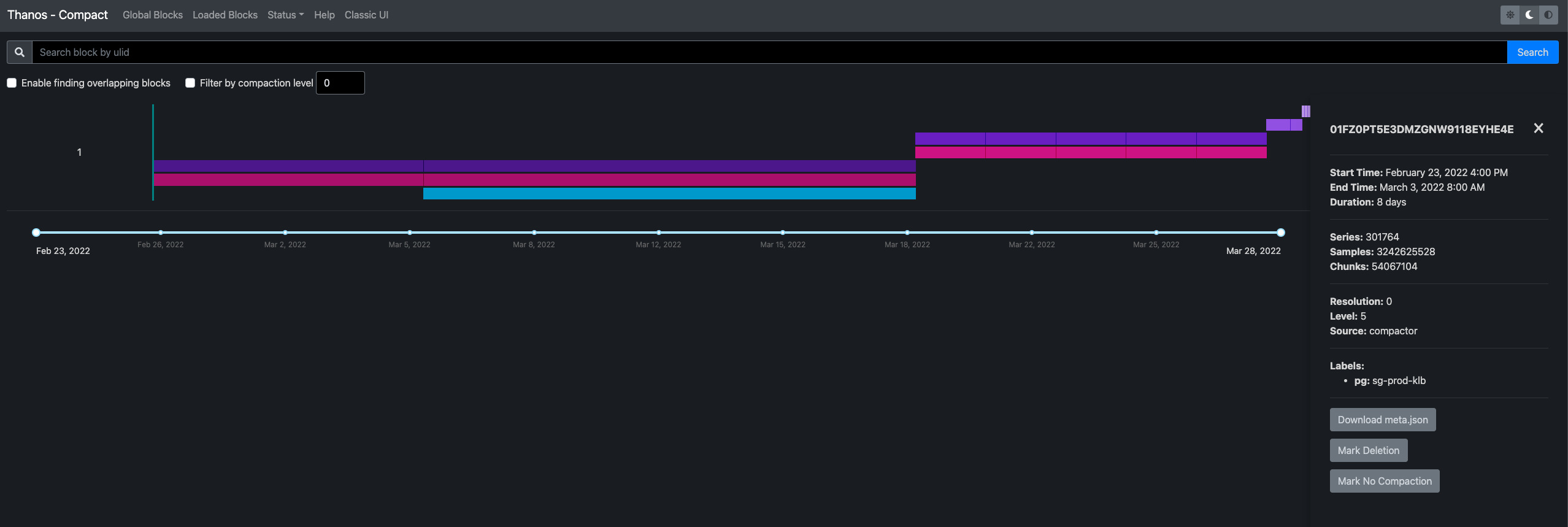
在右下角,我们可以标记删除一个存储块,也可以选择不对其进行降采样。
当打开降采样开关时,Compact 会对所有原始指标数据存储时长大于 40 h 的进行 5 min 采样,对所有 5 min 指标数据存储时长大于 10 day 的进行 1 h 采样。至于,原始数据、5 min 采样指标数据、1 h 采样指标数据保存多长时间,可以通过以下参数配置:
--retention.resolution-raw=90d,原始数据保存最近 90 天--retention.resolution-5m=180d,5 分钟采样数据保存 180 天--retention.resolution-1h=360d,1 小时采样数据保存 360 天,0d 代表永久存储
这意味着,我们只能看到全年 1 h 采样的序列,而局部看不半年前,1 h 之内的任意细节数据;只能看到半年 5 min 采样序列,而局部看不到三个月前,5 min 内的任何细节数据。
为了避免冲突,一个 Bucket 也只允许运行一个 Compact。而 Compact 的参数,直接决定了一个存储 Bucket 的生命周期。
当业务规模庞大时,不可能只用一个 Bucket 存储全部监控数据,即使对象存储的性能已经非常好。我们依然需要对数据存储进行拆分,如下图:
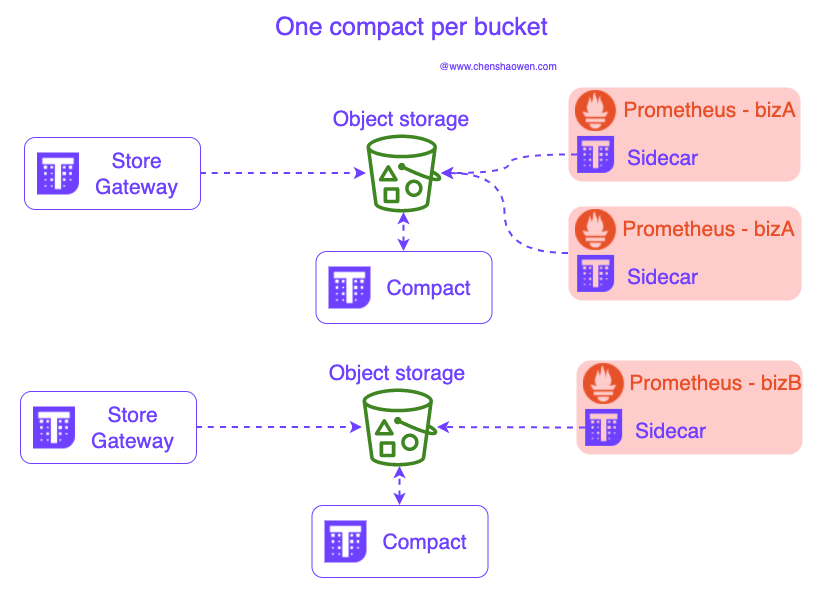
每一个 Store Gateway 都需要配置一个 Bucket 桶,而一个 Bucket 只允许一个 Compact。可以根据以下维度进行划分 Bucket:
- 结算方式
- 所在区域
- 所属业务
- 基础设施层级
- 单指标的横向拆分
3. 将 Prometheus 的存储周期设置为 6 h
刚使用 Thanos 时,会碰到两个迷惑的地方:
- 怎么没有最近 2 h 的数据
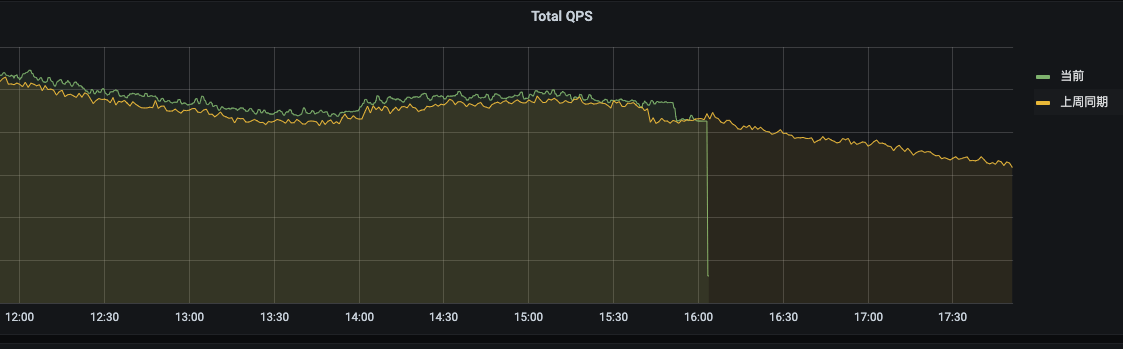
因为没有配置 Prometheus 的查询源。
- 怎么查询速度没有提升
因为 Prometheus 查询源的存储周期太长了。
答案在下面这张图里:
- Sidecar 模式下,每隔 2 h 上传一次数据,因此如果只配置 Store Gateway 的地址,那么 Query 组件将只能查询到超过 2 h 的数据。
- 当 Prometheus 设置的存储时间太长,就会导致 Query 查询长周期数据时,不能有效利用 Store Gaway 查询降采样数据,而需要等待 Prometheus 也返回结果,不能提升查询性能。
- 只有将 Prometheus 源以 Sidecar 的 Grpc 的形式接入到 Query 组件并将其设置为短周期时,才能感受到 Thanos 带来的查询性能提升。
通常,将 Prometheus 的 --storage.tsdb.retention.time 参数设置为 3 倍的 Sidecar 上传存储块的周期,也就是 3 * 2 h = 6 h 即可。
4. 调优 Store Gateway 加速查询
Thanos Store 组件基于对象存储中的指标数据,对外提供给 Thanos Query 查询接口。Store 组件提供了一些可以优化查询的参数。
4.1 设置缓存
--index-cache-size=250MB 默认会使用内存缓存,加速查询。其他可选的缓存包括,memcached、redis。
4.2 设置查询范围
--min-time 和 --max-time 参数可以指定当前 Store 能查询的数据范围。
可以直接根据 RFC3339 规范指定 -min-time=2018-01-01T00:00:00Z,--max-time=2019-01-01T23:59:59Z,也可以指定一个相对时间 --min-time=-6w,--max-time=-2w 只允许查询 2 个星期前但是不超过 6 个 星期的数据。
这种方式不仅可以控制查询范围,还可以加快接口数据的返回,屏蔽不必要的查询结果。
另外一个优化的方向是使用 Query Frontend 组件,同样是借助缓存加速查询响应。
5 重新设计标签系统
使用 Thanos Query 合并多个 Prometheus 数据源之后,遇到的首要问题就是,怎么区分不同数据源的数据。如果没有提前规划好 external_labels 将会导致各种环境、区域下的指标数据混淆在一起,根本无法使用。
如下图,在每一个 Prometheus 实例中都需要设置一些必要的 Labels 信息,以区分不同的 Prometheus 实例数据。
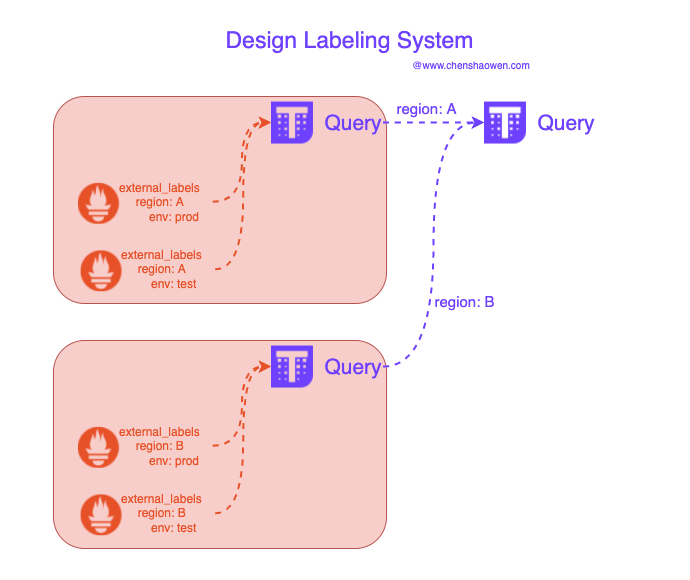
另一方面,在查询和使用监控指标数据时,也需要带上这些标签。这部分的工作量会体现在修改 Grafana 的展示面板和查询 API 的参数调整上。
6. 总结
本篇主要是在生产环境下使用 Thanos 的一些思考和总结。刚开始使用 Thanos 时的目标是,能够部署起来;部署到线上之后的目标是,能够用起来;最后的目标是能够预见一些未来的问题,提前解决掉。
